Previously we put together the backbone of this project:
Project background and data warehouse selection
Build a unified semantic layer
Data querying layer based on controlled IR
And verified in the previous article:
Humans can stably perform data querying based on unified business semantics.
But if the project only stops at this step, it will still be little different from the ordinary Ask-Data demo.
The original intention of this project is not just "can humans look up numbers in natural language", but:
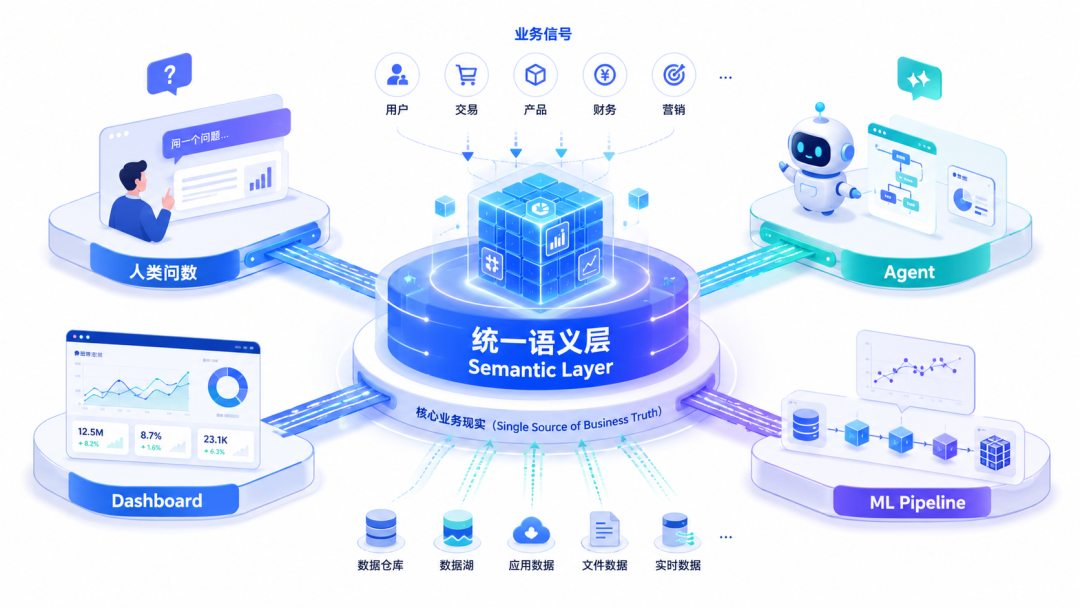
Can the same set of business semantics serve human data querying, Agent invocation, Dashboard display and machine learning at the same time?
The issue moving forward in this article is: in the intelligent era, unified semantics should not stop at the data querying interface, but should continue to serve multiple intelligent system entrances.
1. Data querying is the entry point, not the end point.
If Ask-Data is regarded as a separate function, then the closed loops in the first four articles are actually enough:
Natural Language Questions ↓ Controlled Planner ↓ Cube Query ↓ Answer Generation
But the problem is, real business systems rarely stop at "asking a question."
Data querying itself is of course valuable. It can help humans discover signals faster, understand the current situation, and assist in judgment. Just looking at a longer business chain, data querying is usually not the end point, but more like an entrance: users hope not only to "know what happened", but also hope that the system will continue to support observation, analysis, decision-making, execution and optimization.
As long as the system wants to move forward, it will almost certainly continue to have three types of needs: allowing Agents to proactively analyze, judge, and execute; fixed view display, which deposits high-frequency issues into dashboards and risk panels; and feature reuse, which continues to send these indicators and signals into the model processing process.
If these requirements have their own set of logic, then although the system will have richer functions on the surface, the bottom layer will be divided:
A set of calibers for data querying interfaces
Agent a set of calibers
Dashboard a set of calibers
ML pipeline another set of calibers
It ended up running everywhere, but nowhere was it really reliable.
Therefore, data querying is just the first entry point to get through. From a greater value perspective, the significance of unified semantics is to allow subsequent higher-value capabilities to be built on the same set of business semantics.
2. Multiple entrances are based on a unified semantic layer
On the surface, Agent, Dashboard and ML are three different types of capabilities; but in essence, they are all doing the same thing: defining business semantics. If this matter is not handed over to a unified semantic layer, the system will quickly become fragmented.
Agent, as the executor of intelligent era, cannot bypass the semantic layer.
Now everyone has seen the changes in the working model of the intelligent era: more and more specific business executions will be agents, and humans are more responsible for defining goals, orchestrating agents, and reviewing results.
However, if the Agent wants to start independent analysis, judgment, and execution, the first thing to ensure is that the way to access business semantics must be stable and trustworthy, and behind this is the semantic layer.
As before when talking about the data querying layer, the Agent should not directly connect to the database, nor should it bypass the semantic layer to determine the query structure. However, when it comes to the Agent scenario, the requirements for stability and trustworthiness will be higher: even if the data querying interface answers an incorrect question, it is usually a one-off; once the Agent is connected to the workflow, the error is likely to continue to propagate downstream. For an execution system, the real danger is not whether it can speak, but whether it is stable.
For example:
Misjudgment of which price range is more worthwhile ↓ Misjudgment of which products have opportunities ↓ Generating wrong analysis conclusions ↓ Outputting wrong listing suggestions
If the Agent checks the database directly, it will not only face the problem of unstable caliber, but also the problem of "reinterpreting the business definition for each task". One understands it this way today and another way tomorrow. The same indicator has different meanings in different tasks. Even if such an Agent looks very smart, it will be difficult for it to truly stably enter the business process.
A more reasonable approach is to let the Agent complete these analyzes and calls through a semantic interface constrained by the semantic layer, for example:
ask_metric find_opportunity_products detect_quality_risk_products analyze_competitor_reviews generate_listing_brief
The significance of these interfaces is that the input boundaries are stable, the definitions of internally referenced indicators are stable, and the output results can continue to be reviewed.
In other words, the Agent here does not "understand the database by itself", but:
Through a layer of clear semantic interface, the system has unified business semantics.
From this perspective, the significance of the semantic layer to the Agent is not just an auxiliary layer for analysis, but also a layer of stable business constraints for the agent before it actually enters the business process.
Dashboard is a fixed view of high-frequency issues
In the past, in many teams, Dashboard and data querying systems were often built in parallel, and tables were usually built specifically for Dashboard, or even for each module in it, to wash data. Of course it works in the short term, but in the long term it's easy to have a problem:
The results the user sees in the chart may not be exactly the same as the results asked in the data querying system.
As long as this situation exists, the credibility of the entire system will quickly decline. To keep each application consistent, the maintenance cost will be very high.
A reasonable approach is that Dashboard cards and charts directly reference the indicators formally defined in the semantic layer, and are naturally consistent with the data querying interface.
In other words, the real value of Dashboard is not just "visualization", but:
The high-frequency issues that have been verified in the semantic layer are further precipitated into fixed observation panels.
ML Pipeline should not redefine a set of business semantics
When many systems are connected to machine learning, one of the most likely things to happen is to re-separate them.
There is one set of logic for business analysis, another set of logic for training scripts, and another set of logic for feature engineering. In the end, the model was indeed trained, but it is difficult to say clearly whether the "review growth" and "opportunity signals" used during training are the same definitions as those seen in the product.
This is also a point emphasized from the beginning of this project:
Machine learning features should also be obtained from the semantic layer, rather than the training script itself defining a separate set of query logic.
This is not for the sake of formal unity, but to really solve three problems.
First, the training is consistent with the online caliber. If the model learns a different set of feature definitions from the business system, it will be difficult for it to stabilize the service business in the long term.
Second, characteristics are traceable. When model results require interpretation, it should at least be possible to trace back to what formal business metrics the score relied on.
Third, subsequent maintenance costs are lower. If the negative review definition, price band definition, and risk signal formula are adjusted in the future, changing only the semantic layer is usually much more controllable than changing a dozen training scripts and downstream queries at the same time.
Therefore, for machine learning, the meaning of semantic layer is not only “convenient data access”, but also:
Bind both business systems and training systems to the same set of formal analysis definitions.
But we only talk about it here, and we still stay at the level of principles. For this specific project, we need to continue to answer a more practical question: If we really want Agent, Dashboard and ML to continue to move forward based on the same set of semantics, which layer is most lacking in the current implementation?
What is missing is not a few more indicators, but a formal connection between structured indicators and review textual evidence.
3. In order for multiple entries to continue to share the same set of semantics, what layer is missing?
Back to the project code, so far, the project already has products, reviews and product day indicators, as well as trend and heuristic signals. To continue to advance in the direction of Agent, Dashboard and ML, the project also needs to add an intermediate table that connects comment evidence and structured semantics:
fact_review_insights
It can be understood as a fact table enhanced by comment semantics. It is not an original comment table, nor a final indicator table, but further organizes the comment text into reusable structured insights, such as the sentiment corresponding to the comment, the aspects involved, the pain points summarized, the evidence fragments, and the subsequent aspect clustering, risk labels, and opportunity labels that can continue to be expanded.
From a granular point of view, what this table records is not "how a certain product is generally", but "what semantic facts are identified in a certain comment." If a review involves packaging, smell, and effects at the same time, it can theoretically be split into multiple reusable insight records.
For example:
review_id = R123 aspect = packaging pain_point = packaging leak sentiment = negative evidence_span = "the bottle leaked during shipping"
In this way, the data querying system can quote representative evidence, the Agent can analyze the pain point distribution, the Dashboard can display the aspect clustering results, and ML can continue to consume these structured features.
In other words, it can be understood as a formal translation layer between the review text and the upper business semantics.
The importance of this table is not that it is “one more table”, but that it may become a bridge between the semantics of the review text and the structured analysis of the system.
For example, a negative review should not always exist only as a piece of original text. It can also be gradually enhanced to:
sentiment = negative aspect = packaging pain_point = packaging leak evidence_span = "the bottle leaked during shipping"
Once the system has such a layer, many things will really start to become possible:
The data querying system returns representative evidence
Agent analyzes where negative reviews are concentrated
Dashboard shows the distribution of negative aspects
ML pipeline uses aspect / pain point related features
So from an architectural perspective, fact_review_insights is the key middle layer for “moving from a structured indicator system to an evidence-driven system”.
Conclusion
This article explains:
The value of unified semantics is not to make a question and answer interface more standardized, but to allow humans, agents, dashboards and ML to work based on the same set of business semantics.
If the core question of the first four articles is "how to build this system", then the core question of this article is:
Why should unified semantics not only serve a question and answer interface, but should become the shared data access infrastructure of the entire business system?
And when this question is continued to be asked, it will eventually come down to how to correctly build the enterprise agent in the intelligent era:
**If Ask-Data, Agent tools, Dashboard and ML Pipeline ultimately share the same set of business semantics, then shouldn’t “Ask-Data” itself be understood as an isolated function, but rather as a basic capability of the intelligent era enterprise business Agent? **
This also echoes the point discussed in "Looking at the general enterprise agent architecture from Anthropic Financial-Services" before.
The complete code will be open source on github: xuanagi