There are many developers studying Agent now. Most developers’ research on Agent is based onPersonal AgentImplementations, such as OpenClaw and Hermes-Agent. However, some implementation mechanisms of enterprise agents are different from personal agents, especially memory.
Today we analyze what kind of memory mechanism is needed for enterprise agent, as a reference for teams and developers who need to implement enterprise agent.
The "enterprise agent memory" in this article is not the Agent's private long-term memory in the narrow sense, but a complete set of memory and context infrastructure that the enterprise agent can access, reference, update, and audit when executing tasks, including session state, candidate memory, organizational knowledge, authoritative business systems, relationship graphs, process assets, and audit logs.
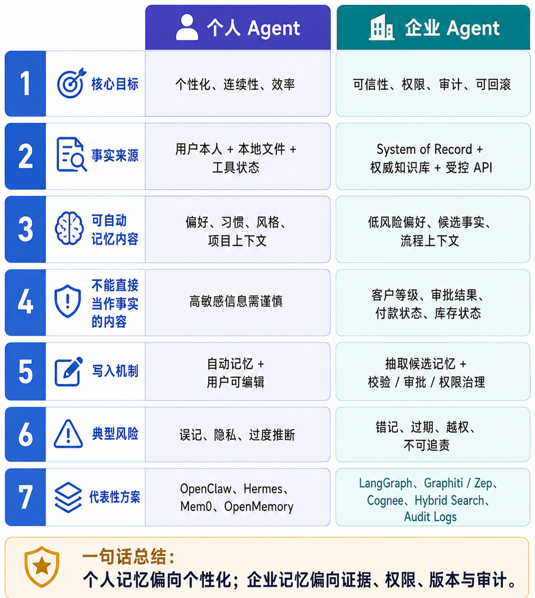
Generally speaking, the memory of a personal agent is biased toward "personalization" and "continuity"; the memory of an enterprise agent is biased toward "evidence, permissions, versions, auditing, and rollback."
In other words, if the personal agent remembers "I like concise replies" and "default TypeScript", it can bring a better user experience; but the enterprise agent cannot casually regard "the user said customer A is a VIP" as fact. True customer hierarchy must come from a CRM, contract, order, or approval system.
We first sort out the common memory types of current Agents, and then analyze what kind of memory mechanisms are needed by personal Agents and enterprise agents respectively.
Agent's memory type
The current Agent memory can be roughly divided into the following seven categories based on memory objects and usage scenarios.
In addition, from the perspective of information sources, Agent memory can also be divided into two categories:
- endogenous memory: Precipitation from the Agent's interaction with users, tasks, and tools, such as session history, user preferences, historical tasks, and automatically updated skills.
- external memory: From external systems such as knowledge bases, business systems, document libraries, CRM, ERP, etc. Knowledge base RAG retrieval can be regarded as an "external retrieval memory/reference memory" of the Agent, but it is not the Agent's own long-term memory.
| memory type | effect | Typical implementation | risk |
|---|---|---|---|
| short term memory / conversational memory | Remember the current conversation and current task status | message history、checkpoint、session store | The context is too long and old information interferes with |
| User portrait memory | Remember preferences, habits, communication styles | saved memories、profile facts、Markdown、JSON | Misremembering, over-inference, privacy |
| episodic memory / episodic memory | Remember what happened in the past, such as the last time a project was discussed | conversation logs、timeline、semantic search | Old, expired facts retrieved |
| Semantic memory / Semantic memory | Remember stable facts, project background, knowledge, such as a project using PostgreSQL database | fact extraction、structured fact store、knowledge base、vector index | LLM extraction of facts is unreliable |
| Entity/Relationship Memory | Remember the relationships between people, customers, projects, and products | knowledge graph、temporal graph | Conflict, timeliness, permissions |
| Procedural memory / Procedural memory | Remember the "how" | skills, runbooks, SOP, code scripts | Untested processes are automatically executed |
| Audit memory / Audit memory | Remember why the Agent did what it did | trace、tool logs、retrieval logs、approval logs | If it is missing, the company cannot be held accountable |
Development frameworks such as OpenClaw, Hermes-Agent agents, and LangGraph, which have received recent attention, all use multiple memory methods in a comprehensive manner.
The following is a summary of mainstream Agent memory related solutions. It should be noted that this table is not a strictly horizontal comparison at the same level, but a positioning of common components in the current Agent memory ecology.
| plan | core mechanism | personal agent | enterprise agent |
|---|---|---|---|
| OpenClaw Memory | Markdown memory、daily notes、dreaming、memory search | Great for local personal assistant | Can be used for small team experiments; enterprises require additional permissions, audits and approvals |
| Hermes Agent Memory | MEMORY.md + USER.md + session search + learning loop | Great as a long-term personal assistant | Self-generated memories/skills cannot be put into production directly |
| Mem0 | Automatic extraction, user/session/agent multi-level memory, hybrid retrieval | Great for personal long-term memory and cross-instrument memory | Can be used for low risk appetite or candidate memory; corporate facts need to be verified |
| OpenMemory | Project-level coding memory, access logs, visibility rules | Very suitable for developers as personal coding agents | Can be used as an engineering team tool, but requires enterprise IAM/repo permissions |
| Letta / MemGPT | core memory + archival memory, agent can read and write independently | Suitable for long-term self-maintenance agent | Can be used as agent working memory; authoritative data writing needs to be managed |
| LangGraph Memory | checkpoint + store, engineering status management | Suitable for complex personal workflow | Session state and long-term store infrastructure ideal for enterprise processes |
| LlamaIndex Memory | static / fact / vector memory blocks | Suitable for document-based personal assistants | Suitable for enterprise RAG agent, but fact extraction should be a candidate |
| CrewAI Memory | LLM automatically analyzes scope / category / importance | Suitable for multi-agent prototypes | Enterprises should use automatic writing with caution and approval and audit are required. |
| AutoGen Memory | memory protocol, customizable implementation | Flexible but requires development | Suitable for self-developed enterprise memory, but must be managed by yourself |
| Zep / Graphiti | temporal knowledge graph、provenance、validity window | Suitable for complex personal relationships/long-term projects | Suitable for dynamic enterprise context and relationship facts |
| Cognee | graph + vector + connectors + ACL | Individuals are often overweight | Suitable for organizational-level "company brain" and cross-system knowledge unification |
| Honcho | Deep user modeling, peer-centric memory | Perfect for highly personalized assistants | Only suitable for explicitly authorized low-risk personalization scenarios |
| Vector DB / Hybrid Search | semantic + keyword retrieval | Suitable for personal knowledge base | Enterprise RAG infrastructure, but not full trusted memory |
How should personal intelligence design memory?
personal agent goals
The memory goals of the personal agent are:
personalization
continuity
Editable
low cost
Privacy controllableIn personal scenarios, the authoritative source of much preference, habit, and style information is the user himself. If the user says "I like concise answers" or "My blog is in this directory", the Agent can directly write it down; if the user makes a mistake, the user can correct it.
But there are also some facts in personal scenarios that are best obtained from external tools or file systems, such as calendar time, email content, file paths, order status, code warehouse status, etc. Therefore, personal Agents can accept a certain degree of automatic memory, but they also need to allow users to view, modify, and delete.
Recommended architecture
Personal agents can adopt the following memory architecture:
Short term memory:
Session history / checkpoint / compaction
Long-term preference memory:
OpenClaw MEMORY.md / Hermes USER.md / Mem0 / OpenMemory
Episodic memory:
Past conversation log + semantic search
Optional Zep/Honcho
Project memory:
project-scoped memory
AGENTS.md / skills / runbooks
User controls:
View, edit, delete, disable, temporary chatsThe following are architectural recommendations for three typical scenarios.
Recommended combination A: Lightweight personal assistant
OpenClaw / Hermes
+ Markdown memory
+ Conversation search
+ User manual editingPerfect for everyday personal assistant. The advantages are simplicity, transparency and controllability.
Recommended combination B: Long-term personal assistant
OpenClaw / Hermes
+ Mem0 / OpenMemory
+ Vector database Milvus/pgvector
+ Users can view, edit and deletePersonal Agent suitable for long-term use. OpenClaw's Markdown memory is very suitable for individuals because the files are visible, editable, and backupable; if you add Mem0 / OpenMemory, you can get better automatic extraction and cross-tool retrieval.
Recommended combination C: Project Assistant
OpenMemory / Mem0
+ project memory
+ project notes / repo notes
+ AGENTS.md / project description file
+ skills / runbooks
+ Local vector library / pgvectorSuitable for individuals or small teams working around projects, such as personal software project development, consulting projects for one-person companies, content projects, customer delivery projects, etc.
It can remember:
Project goals
Project background
System architecture
technology stack
test command
Customer needs
The pits that have been stepped onProject assistants are different from regular personal assistants. Ordinary personal assistants mainly remember user preferences and daily context; project assistants place more emphasis onproject scope. The same person may be working on multiple projects at the same time, and each project has different goals, rules, materials and processes.
Therefore, the project assistant requires:
global user memory
+ Project-level memory
+ Project Information / Warehouse Rules
+ Reusable skillsWhy personal agents can use automatic memory
Personal memories are usually:
Preference: What I like
Habitual: How I usually do it
Project Type: What am I doing?
Contextual: where we talked last time
Style type: How do I want you to answerMuch of this content is subjective, low-stakes, and the users themselves are often the final judge. Therefore, "automatic memory + user editable" solutions such as Hermes, OpenClaw, OpenMemory, and Mem0 are very suitable for personal agents.
How should the memory of enterprise agent be designed?
Enterprise agent goals
The memory goals of enterprise agents are different from those of personal agents:
Credibility > Permissions > Traceability > Timeliness > Auditing > Rollback > PersonalizationThe biggest problem in the enterprise is not that the Agent cannot remember;It remembers things that should not be remembered, are wrong, expired, and do not have permission, and use them for business actions。
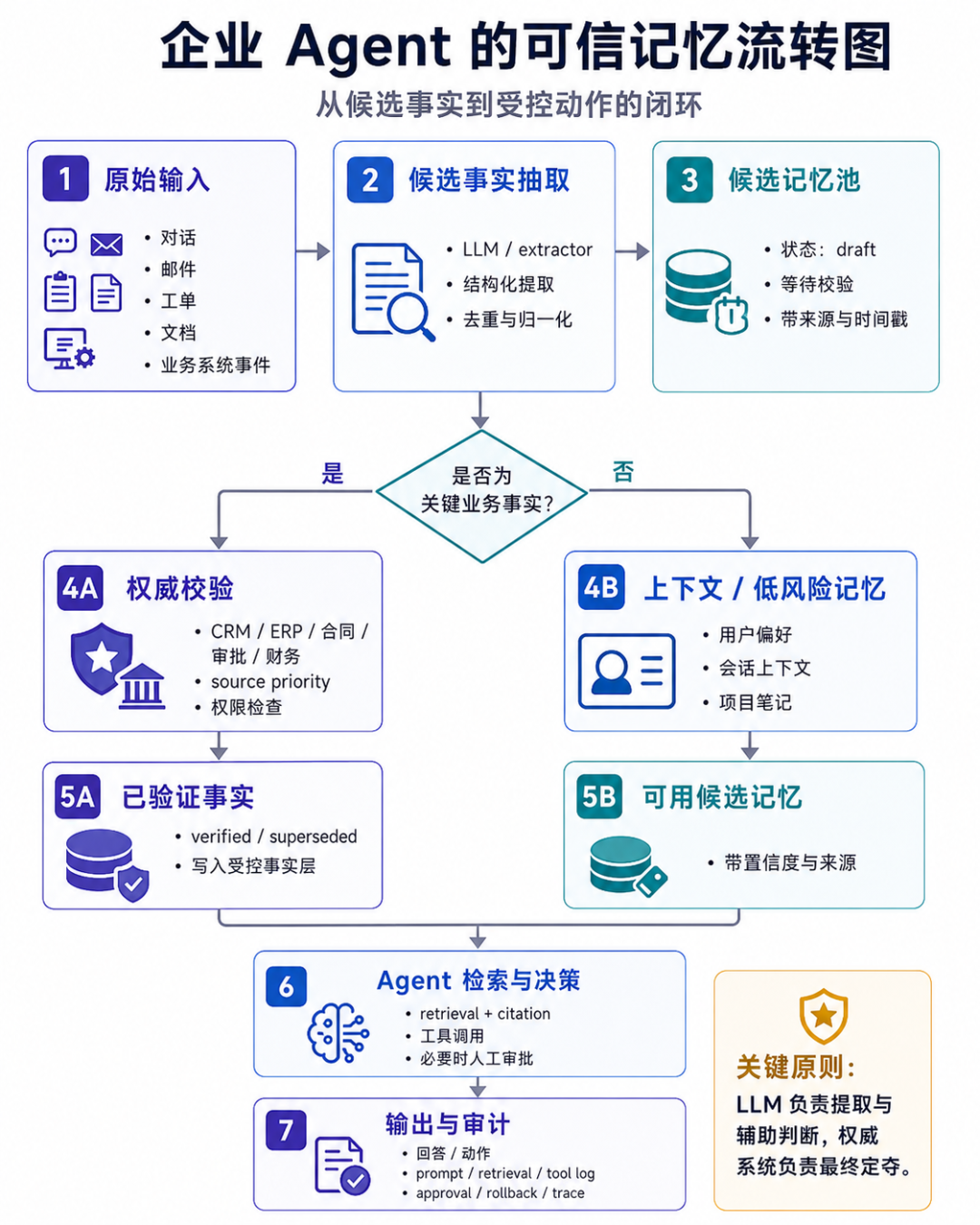
Layering of Enterprise Memory
The memory of the enterprise agent should be multi-layered and collaborative, such as the following layered architecture:
L0 session state
- Current task, current conversation, temporary intermediate results
- LangGraph checkpoint / OpenAI session / DB session
- Not used as a corporate source of fact
L1 candidate memory
- Candidate facts extracted from conversations, emails, and tickets
- Status: draft / verified / rejected / superseded
- Available Mem0 / LlamaIndex FactExtraction / self-developed extractor
L2 authoritative source of truth/system of record
- CRM, ERP, HRIS, contract library, order library, financial system, approval system
- Agent can only be retrieved by permission or written via controlled API
- The facts are subject to the system of record
L3 Authoritative knowledge and retrieval memory
- Policy library, document library, code library, meeting minutes, knowledge base
- hybrid search + reranker + citation + ACL
- Weaviate / Qdrant / Milvus / Elasticsearch / Azure AI Search / pgvector
L4 Relationship/Time Memory
- Customer relationships, organizational relationships, project status, fact changes
- Zep / Graphiti / Cognee / knowledge graph
L5 program memory
- SOP, runbook, skills, approval process, code template
- Git management, testing, review, version, rollback
L6 audit memory
- prompt、retrieval、tool call、memory write、approval、output
- Used for accountability, evaluation, compliance, and reviewThe core of this architecture is:LLM can generate candidate memories but cannot directly create corporate facts.
Recommended combination A: Corporate knowledge Q&A/RAG
Suitable for: system Q&A, R&D documents, contract terms, customer service knowledge base, and sales enablement.
LangGraph / LlamaIndex / Dify-like workflow
+ Corporate document analysis
+ ACL synchronization
+ Weaviate / Qdrant / Milvus / Elastic / Azure AI Search / pgvector
+ hybrid search
+ reranker
+ citation
+ audit logsThe point here isn't "remember long term";Retrieve authoritative knowledge by authority and give the source。
Enterprise document Q&A should not only rely on automatic summary memory, because information such as contract number, policy number, product model, customer name, date, etc. need to be accurately matched and is usually more suitable for hybrid retrieval.
This combination is suitable for solving:
What should be done according to company policy?
How to interpret a certain contract clause?
How is a system deployed?
How to configure a certain product function?But it is not suitable for directly saving dynamic business facts such as customer status, approval results, inventory status, payment status, etc. These should come from authoritative sources of truth such as CRM, ERP, financial systems, order systems, approval systems, etc.
Recommended combination B: Customer 360 / Ticket / Sales Context
Zep / Graphiti or Cognee
+ CRM / work order / contract / bill / email / meeting minutes
+ temporal facts
+ provenance
+ entity resolution
+ source priority
+ ACLZep / Graphiti is suitable for this type of scenario because business facts are often time-varying: customer contacts change, contract status changes, project leaders change, SLAs change, whether the issue has been resolved changes.
Graphiti's facts have a validity window and can be traced back to episodes; this is more suitable for answering than ordinary vector chunks:
What's going on now?
What was the situation before?
When did it change?
Where does this conclusion come from?Cognee is more suitable for the "company brain" or unified memory across systems because it emphasizes connectors, entity resolution, granular access control, graph + vector search, and enterprise traceability / audit capabilities.
It should be noted that emails and meeting minutes are generally more suitable as candidate sources of fact or context; CRM, work orders, contracts, and billing systems are higher priority authoritative sources of fact.
This combination is suitable for answering:
Who is responsible for this customer now?
What high-priority tickets has this customer had in the last 90 days?
When did this customer's SLA change?
Which product and contract is associated with a work order?Ordinary RAG alone is often not enough for such problems because they are not only document retrieval problems but also entity relationships, state changes, and time validity problems.
Recommended combination C: Enterprise process execution agent
Suitable for: reimbursement, procurement, approval, IT operation and maintenance, HR entry and exit, sales follow-up.
LangGraph
+ checkpointer
+ PostgreSQL store
+ policy engine
+ tool call audit
+ human approval
+ System of record APIThe focus of this type of Agent's "memory" is not to remember preferences, but to remember process status:
What step are you currently on?
who approved
Which tool was called
What was the reason for the last failure?
Whether manual confirmation is required
Do you need to roll back?In enterprise processes, automatically extracted memories such as Mem0 can assist "user preferences" or "historical interactions", but they cannot determine the approval results. Approval results must come from the approval system, payment status must come from the financial system, inventory must come from the ERP, and customer levels must come from the CRM.
Conclusion
Although enterprise agents and personal agents are both intelligent agents, their memory requirements are different.
Personal memory can be a little more automatic, because for a lot of preferences, habits, and style information, the user himself is the judge of fact.
The memory requirements of enterprise agent are:
Every business judgment has a source
Every action is authorized
Every fact can be tracedThe long-term memory subject of an enterprise agent should not be the Agent's private memory, but the externalized and controlled organizational memory, including knowledge bases, business systems, maps, process assets, and audit systems.