Ask-Data refers to intelligent data query of structured data (database, Excel).
Before the emergence of large models, some BI systems used predefined data sets, field aliases, synonyms, and rule templates (slot filling) to map natural language to fields, filter, sort, and aggregate, thereby achieving a certain degree of self-service data querying.
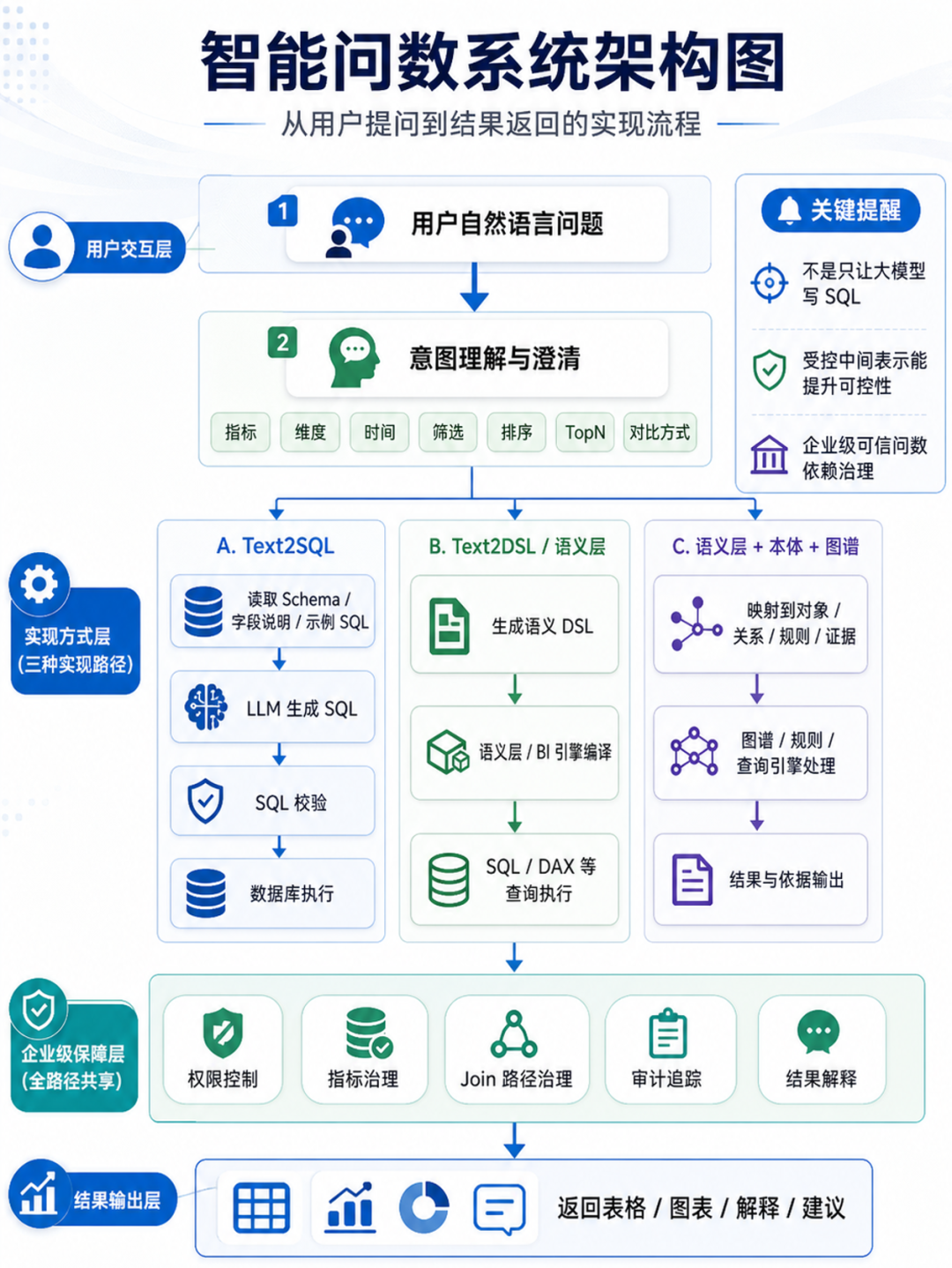
After the emergence of large models, generating IR or SQL based on the ability of large models has become an important technical direction of Ask-Data. The current mainstream Ask-Data has the following technical routes:
Route 1: Text2SQL
A large number of teams that hope to explore Ask-Data with the help of large models will naturally adopt this technical route.
User issues
→ Read schema / sample SQL / field description
→ LLM generates SQL
→ SQL validation
→ Database execution
→ Return to Table/GraphIn scenarios with single tables, small wide tables, clear field meanings, and simple calibers, Text2SQL often only requires schema, field descriptions, sample data, and a few SQL examples to start. The technical process is very intuitive and best reflects the direct use of large model capabilities. The documents of langchain and dify also provide examples of this route.
For simple scenarios of single table/small wide table data querying, this route is suitable and the fastest to implement. In addition, if it is used by data developers and analysts, since the users themselves are very clear about the underlying data, there is no problem in using it. But if the scene is a little more complicated, many problems will soon arise.
Text2SQL features:
| Dimensions | Performance |
|---|---|
| advantage | Fast access, suitable for prototypes and structured data |
| shortcoming | High requirements for schema quality, sample SQL, and verification |
| Suitable | Scenarios with clear data structure, few tables, and simple caliber |
| core risk | SQL illusion, join error, indicator caliber error |
Route 2: Text2DSL / Text2Semantic Route
For enterprise-level data querying that pursues trustworthy, manageable, and reusable indicator standards, the Text2DSL/semantic layer route is becoming a more stable mainstream architecture.
Text2DSL does not allow the large model to write SQL directly, but allows it to generate a more controlled intermediate representation (IR) first, such as:
User issues
→ Intent analysis
→ Indicators/Dimensions/Time/Filter/Sort/TopN/Comparison method
→ Semantic Query DSL
→ BI engine or semantic layer generates SQL / DAX / LookML Query / SemQL
→ execute
→ Explanation of resultsText2DSL mainly solves the clarification (directivity) and constraint issues of business concepts. For example, internal data querying of the sales department, operations department, and financial department:
What is the GMV this month? (What is GMV)
What is the new customer conversion rate? (What is a new customer, what is the conversion rate, what is the new customer conversion rate)
What is the ROI of each channel?
Which products have seen the biggest sales declines? (Sales use that metric)
This type of scenario usually requires a semantic layer (and is basically sufficient for business domains) because it involves:
- Indicator definition
- Dimension definition
- time caliber
- aggregation rules
- Common filters
- join path
In addition, many companies that did data governance in the past had better data warehouse models, such as:
- fact table
- dimension table
- subject area
- Indicator system
- unified dimensional encoding
It is also suitable to use semantic layer at this time, because many object relationships are already reflected in the data warehouse model:
- The order fact table is associated with the customer dimension table;
- The sales fact table is associated with the product dimension table;
- The financial fact table is associated with the organizational dimension table;
- There are standard dimension tables for time, region, and channel.
It should be noted that there are also specialized semantic layer products or projects, such as cube (intelligent era, how to build an enterprise's trusted data foundation).
Text2DSL features:
| Dimensions | Performance |
|---|---|
| advantage | More controllable, more explainable, and more suitable for enterprise level |
| shortcoming | Need to build semantic layer, indicator layer and object layer |
| Suitable | Complex indicators, complex business calibers, shared by multiple departments |
| core barriers | Semantic layer, indicator management, DSL, query compiler |
Route 3: semantic layer + ontology + map
When data querying moves from a single business domain to cross-department, cross-system, complex object relationships, and requires attribution explanation or combination of document evidence, only the indicator semantic layer is often not enough, and ontology and graph capabilities need to be introduced. The semantic layer is responsible for "how the indicator is calculated", and the ontology map is responsible for "who the object is, what the relationship is, what the context and evidence are".
Typical structure:
business objects/metrics/dimensions/relationships/rules/knowledge
→ ontology/semantic layer/knowledge graph
→ LLM is only responsible for understanding the intention
→ Handle queries and calculations to deterministic enginesIndicator semantic layer: answer "how to calculate"
Object ontology layer: answer "who is who and what is the relationship"
Context/evidence layer: Answer “why, where does the evidence come from, what is the current state?”
The technical route of ontology+map is not to simply let the large model "know more business knowledge", but to explicitly model the core objects, object relationships, indicator calibers, business rules, status events and evidence sources in the enterprise. LLM is mainly responsible for understanding user intentions and mapping problems to governed objects, indicators and relationships; the actual query, calculation, reasoning and traceability are left to the semantic layer, graph engine, query engine or rule engine to complete. This route is suitable for enterprise-level data querying scenarios that involve cross-departments, cross-systems, complex object relationships, and require disambiguation, attribution explanation, or evidence tracing. It is more expensive to build, but also more reliable, explainable, and scalable.
It should be noted that routes 2 and 3 put forward requirements for enterprise data governance, but it is precisely because of data governance that it is possible to achieve trusted data query. Last year, there were many acquisitions of data governance companies in the U.S. AI industry. That is to say, enterprises began to realize that data governance was first needed in the process of agent implementation (enterprise trusted data foundation structure and manufacturer sorting).
Features:
| Dimensions | Performance |
|---|---|
| advantage | Suitable for enterprise-level trusted data querying |
| shortcoming | Modeling is expensive and requires governance capabilities |
| Suitable | Large enterprise, multi-system, multi-indicator, multi-object scenario |
| core barriers | Enterprise object layer, semantic model, graph, indicator management |
AgenticTrends
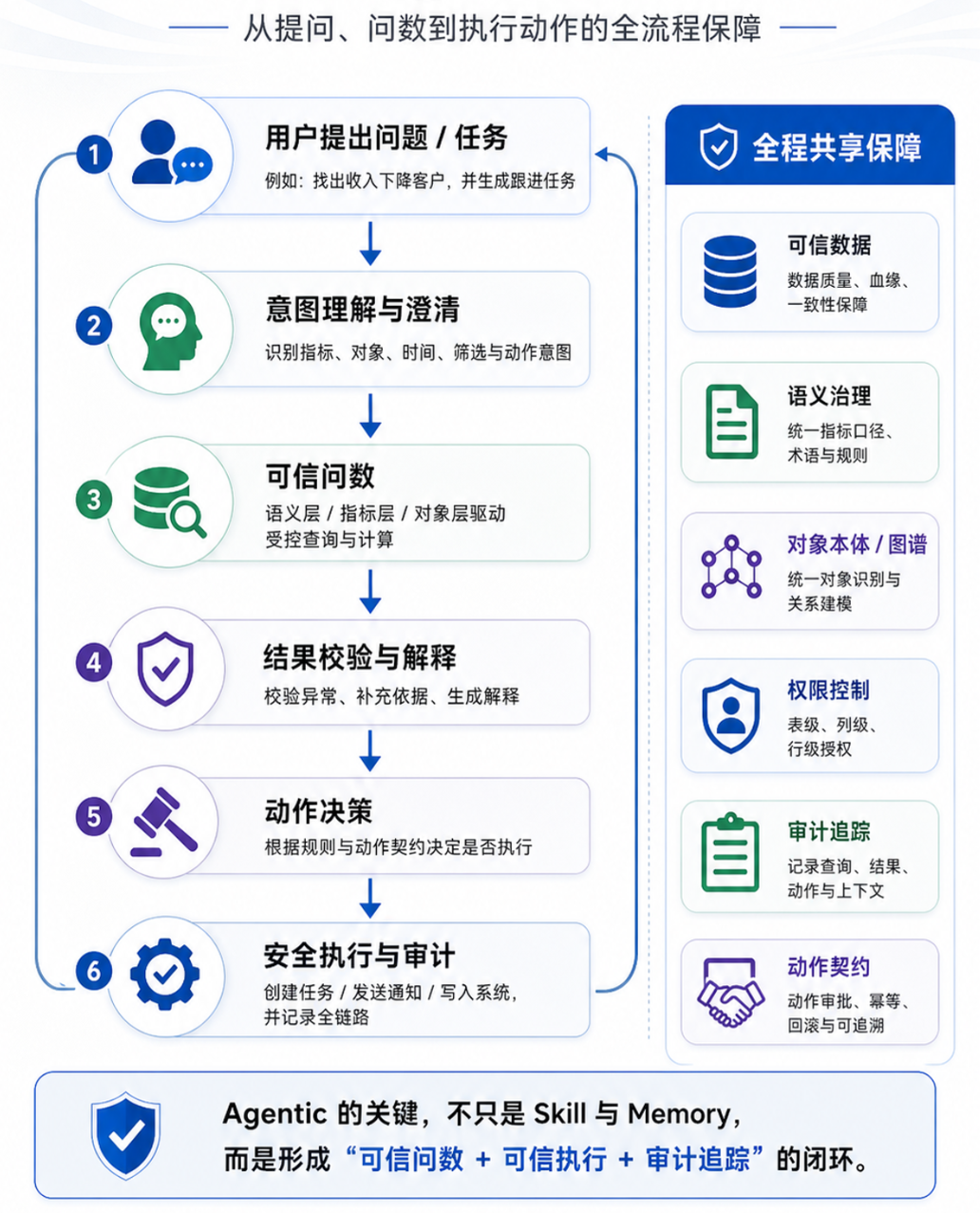
The above route is the basic Ask-Data technology. The Ask-Data system is now developing in the direction of Agentic (action after data querying). For example, a user asked:
Identify the customers with the biggest revenue decline this month and generate follow-up tasks.
Notify the supply chain manager when inventory abnormalities are discovered.
If an indicator drops for three consecutive days, an analysis report and rectification suggestions will be automatically generated.
At this time Ask-Data does not just answer, but enters execution. This is actually an AI service with huge market value recently mentioned by Sequoia Capital and Huang Renxun.
But for Agentic to execute accurately, the system must clearly know:
- Whether the indicator is really abnormal;
- Which objects are affected by the anomaly;
- Who is the relevant person in charge;
- What action should be triggered;
- which systems the action affects;
- What is the basis for the conclusion?
Therefore, this scenario usually requires:
- Semantic layer: ensures that the indicator is calculated correctly;
- ontology / map: ensure correct object recognition;
- State map: ensure that the current context is correct;
- Action contract: Ensure that the action is executed correctly;
- audit trail: ensure traceability.
Conclusion
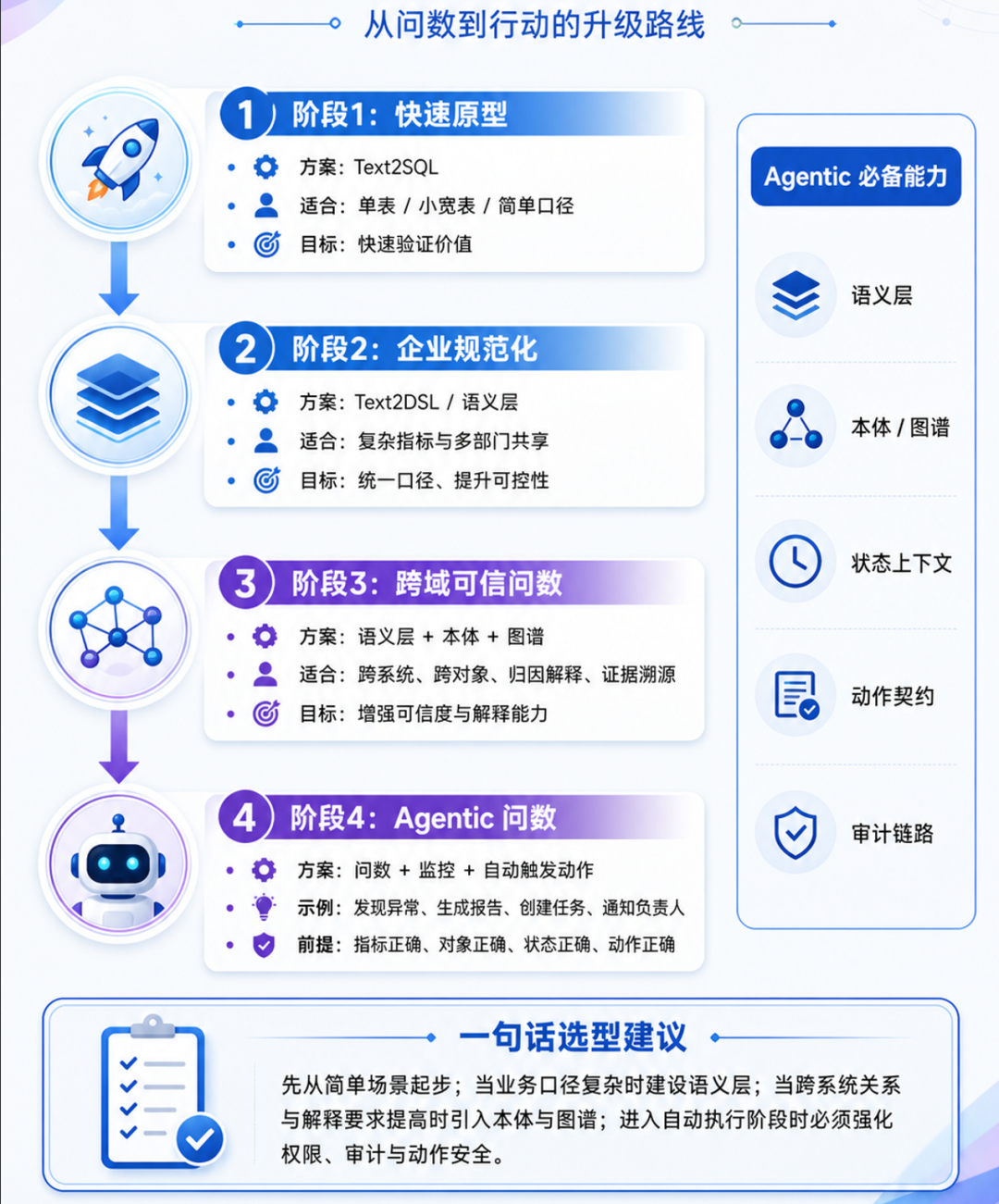
Ask-Data does not simply let large models write SQL. Lightweight scenarios can be started quickly from Text2SQL, but enterprise-level trusted data querying usually requires semantic layer, indicator management, permission management, query compilation, result verification and audit trail. Ontologies and maps are further introduced when cross-systems and cross-objects require attribution and evidence traceability.
In the future, agentic data querying will move from "answering data questions" to "finding problems and triggering actions", but whether it can truly enter the core business of an enterprise depends on whether the underlying trusted technology facilities are complete. Many current Agentic products place too much emphasis on Skill and Memory, but Skill and Memory are only the ability expression layer of the Agent; trusted data, trusted semantics, trusted execution, and trusted auditing are the basis for supporting the Agent's reliable actions.