The previous article "Implementation of Semantic Native Ask-Data System (2): From Public Data to Analyzable Data Warehouse" made it clear: why we started with public data, why we chose All_Beauty, why the original working layer used Parquet, and why the formal analysis layer first converged into three core tables of products, comments and product day indicators.
But if the system only stays here, it is essentially just:
A set of relatively standardized analysis tables.
This is of course much better than reading the original data directly, but it has not yet solved the core problem of this project:
How can human data querying, Agent invocation, Dashboard display and subsequent machine learning truly share the same set of business semantics, instead of being separated in different places?
That’s what this article is going to get into.
The core of this article is not to introduce a tool, but to explain:
Why the semantic layer is the real center of this project.
This article corresponds to the third step of the entire series: on top of the formal data warehouse, precipitate business objects, indicator calibers, relationships and high-frequency analysis logic into formal semantics that can be shared by multiple portals.
1. Why can’t the model be directly connected to the library?
The default path for many Ask-Data demos is:
Expose the database schema to the model ↓ Let the model directly generate SQL ↓ Summarize the query results into answers
This path is straightforward in the demonstration stage, but several problems will soon be exposed: the caliber is unstable, and different algorithms may be written for the same indicator each time; multiple entries are inconsistent, and human data querying, Agent, Dashboard and algorithm scripts each have their own set of logic; interpretability is poor, and it is difficult to stably explain which indicators and time boundaries the results are based on; and maintenance costs will also rise rapidly.
Therefore, a more reasonable path is not to "let the model learn how to look up the table", but to:
First organize business semantics into formal system capabilities, and then let data querying, Agent and other entrances work around this set of semantics.
2. What exactly is the semantic layer solidifying?
The semantic layer here is not "giving the table a more friendly name", nor is it "making a field annotation document".
What it really solidifies are four categories of things:
The first category is business objects: what are products, reviews, and product day indicators, and what is the relationship between them. 第二类是指标口径:评论数、平均评分、差评率、30 日评论速度、质量风险信号这些指标到底怎么定义。 The third category is query logic: which filter conditions, time windows and aggregation methods are officially supported by the system. The fourth category is the reuse boundary: which definitions are to be reused by data querying, Agent, Dashboard and algorithm script.
From this perspective, the responsibility of the semantic layer is not to "make the query look better", but to:
Precipitate business definitions that will be used repeatedly at multiple entrances in the future into a set of formal contracts in advance.
3. Definition products, reviews and productDailyMetrics
For the current project, the Cube semantic layer is first developed around three objects:
products reviews productDailyMetrics
This corresponds to the data layer design in the previous article.
products corresponds to the product dimension. It defines who the products in the system are, what category they belong to, and what price range they are in.
reviews corresponds to the comment fact. It defines review-level metrics such as review count, average rating, number of negative reviews, number of verified purchase reviews, and number of helpfulness votes.
productDailyMetrics corresponds to the product day indicator. It defines trends, change rates and heuristic signals, providing a formal carrying layer for subsequent trend data querying and risk identification.
Together, these three objects can support most of the problems in this implementation scenario:
Which price band is growing faster? Which product has a higher negative review rate? Which products are growing fast but have low ratings? Which commodities have stronger opportunity signals? Which products have higher quality risks?
From the perspective of "semantic nativeness", the value of this step is not just "build three cubes first", but:
First stabilize the most critical business objects and analysis granularity, and then gradually expand review insights, opportunity scores, and evidence chains.
4. What does the semantic layer contain?
In addition to the necessary measures and dimensions, the current project Cube semantic layer also contains:
segments
pre-aggregations
heuristic signal metrics
There are three judgments behind this.
1. segments It should not always be temporarily created by the data querying layer.
For example:
negativeReviews verifiedReviews helpfulReviews activeDays risingNegativeRate
These are not one-time filtering conditions, but business slices that will be reused frequently.
If it is temporarily spelled out every time in the data querying layer, Agent prompt word or front-end query, and it is not a deterministic query, then the definition of these slices will bifurcate sooner or later.
Precipitating them into the semantic layer is equivalent to saying:
This is not a technique for a certain query, but a reuse semantics officially recognized by the business system.
2. pre-aggregations It’s not an optimization that needs to be considered later.
In many systems, pre-aggregation is considered as a later performance optimization.
But in Cube, it has another meaning: it allows the semantic layer to not only “forward warehouse queries”, but to naturally carry high-frequency analysis modes.
For example, rolling analysis by price band, product, and day is itself the most likely to be used repeatedly in subsequent data querying and dashboards. Fixing these patterns with pre-aggregation is equivalent to recognizing them in advance in the semantic layer:
Which analysis paths are used by the system core and query acceleration is performed.
3. Heuristic signals
Now the project adds heuristic business signals:
opportunitySignalScoreAvgqualityRiskScoreAvg
They represent an important direction: the semantic layer not only serves "original indicator queries", but also begins to carry reusable business explanations.
In other words, the system no longer just answers "how many comments are there", but can answer "which products are more worthy of attention" and "which products are more risky".
5. Why is the semantic layer the center of multi-entry consistency?
This project has always emphasized that human data querying, Agent calling, Dashboard display and algorithm feature generation should share the same set of business semantics.
The real implementation of this sentence relies on the semantic layer.
Because only the semantic layer can truly answer these questions stably:
What indicators should we look at for comment growth?
How to define negative review rate?
How to filter out highly helpful negative reviews
How to calculate opportunity signals?
How to anchor the time range?
If these definitions only exist in:
In a data querying interface
in a certain prompt word
in a notebook
In a certain Dashboard SQL
That system is divided.
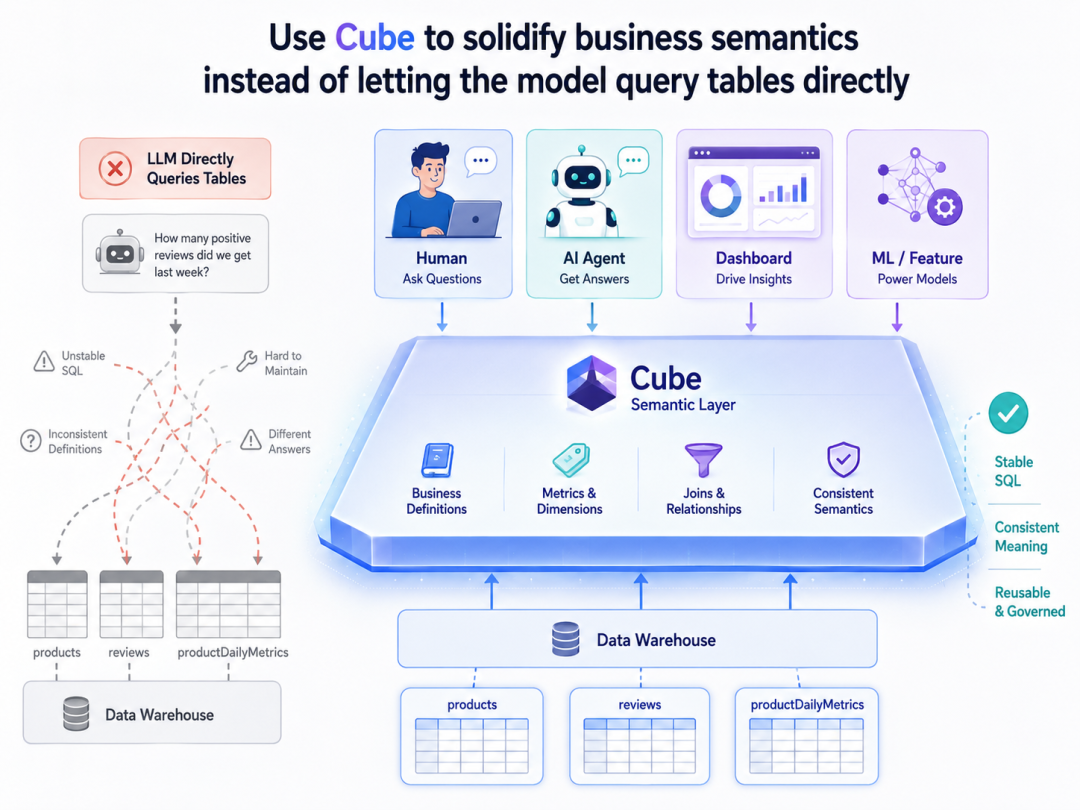
The real value of the semantic layer is that it allows these definitions to start to break away from "a certain call" and become "formal definitions that can be shared by the entire system."
As long as you want multiple portals to share the same set of business calibers, you must need a formal semantic bearer layer.
Conclusion
The previous article addressed "Is there a formal data warehouse?", and this article addressed "How to formally define business semantics above data warehouses."
At this point, we have several tables, and we have:
The three formal business objects are products, reviews and product day indicators.
A batch of indicators and dimensions with unified caliber
reusable segments
Reusable pre-aggregations
Reusable heuristic business signals
But after having a unified semantic layer, the next step is not to let the model generate SQL at will.
The problems to be solved in the next article are:
When these indicators, dimensions, slices, and signals have been formally defined, how should human natural language questions be converged into controlled, stable, and interpretable query structures?
The code of this series of projects will be open source at https://tools.agentstack.space, and interested friends can follow it.