The previous article "Implementation of Semantic Native Ask-Data System (1): Starting with Amazon Product Selection and Competitive Product Reviews" clearly explained the background, positioning and overall structure of this project.
This article starts to get into the real implementation issues:
If such a system is to be built, how should the public data be organized into a set of data models that can be analyzed, reused, and carried by the semantic layer?
This article corresponds to the second step of the entire series: first organize the public data into a formal data base that can be reused for a long time, and then talk about the semantic layer, data querying layer and Agent reuse.
This article is relatively detailed. I hope that even readers who don't know data warehouses can first establish a complete and intuitive understanding of data warehouses and "how raw data enters the formal analysis process" through this article, so that they will not be left hanging when looking at the semantic layer and Ask-Data layer later.
1. Public data selection
As mentioned before, what this project wants to verify is:
In a data scenario with clear boundaries, clear semantics, and easy verification of results, can a unified semantic layer-driven data querying system be established?
Therefore, a more appropriate approach is to choose a starting point that is publicly available, has sufficient samples, and is real enough to analyze the problem. Amazon Reviews 2023 satisfies this condition.
The data set itself is large enough and contains structured information such as reviews, ratings, product metadata, prices, and help votes, as well as unstructured text such as review text and descriptions. It can not only support basic indicator analysis, but also reserve space for subsequent comment semantic enhancement, pain point clustering, opportunity scoring and other capabilities.
Official address of the data set: https://amazon-reviews-2023.github.io/main.html
Hugging Face dataset download address: https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023
At the same time, the complete Amazon Reviews 2023 data set is too large, so we only select the All_Beauty subset.
Description of this subset dataset size:
All_Beauty reviews: 701,528 All_Beauty items: 112,590 Total local raw cache directory: about 1.01 GB - raw_review_All_Beauty: 526.39 MB - raw_meta_All_Beauty: 486.24 MB Total project exported Parquet: about 198.66 MB - all_beauty_reviews.parquet: 144.56 MB - all_beauty_meta.parquet: 54.10 MB
The size of this set of data can be verified on an ordinary development machine.
The subset contains data information in the following dimensions:
Which price bands have seen faster recent review growth? Which products are in high demand, but satisfaction is not high? Which products are mainly focused on with highly helpful negative reviews? Which commodities are experiencing growth but are also experiencing rising quality risks?
2. Completion of the original working layer Parquet
Parquet is Apache Parquet, a columnar data file format oriented to analysis scenarios. It can be understood as a "structured data file with a clear schema, suitable for batch reading and subsequent analysis and processing", between the downloaded original cache and the formal data warehouse table.
Many projects will directly use the cache directory generated by the download tool, or use the original JSON, Arrow, and JSONL as a long-term input layer. For this project, the key is not just "whether the data can be read out", but "whether the system has a layer of data input contracts that it manages by itself."
Parquet The value here mainly has three points: the schema is clear, which facilitates field mapping and type checking; columnar storage is more suitable for subsequent field filtering, aggregation and import into data warehouses; it also provides a layer of original data boundaries managed by the project itself, making it more stable when expanding categories or migrating data warehouses.
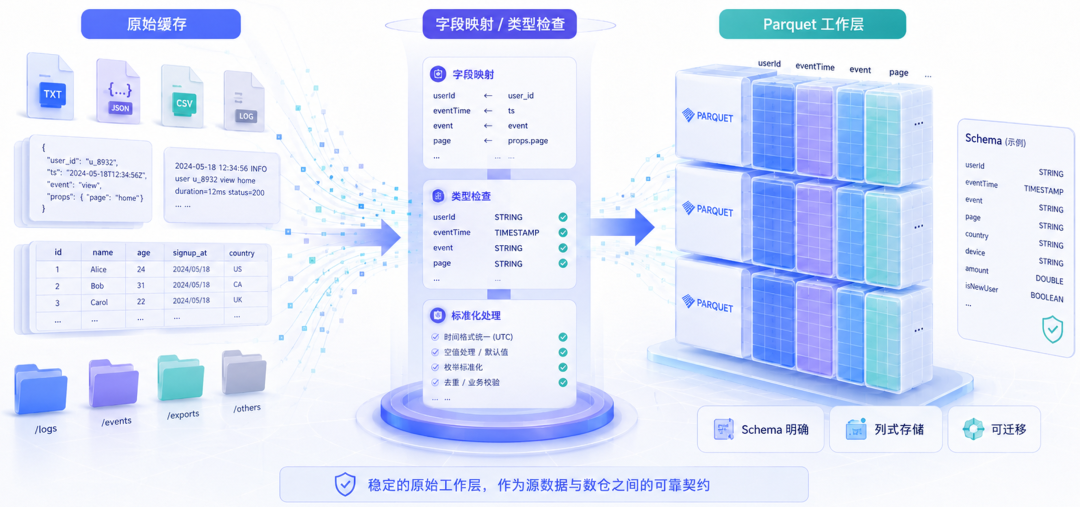
So the key here is not that "Parquet is technically more advanced", but rather:
When a system wants to precipitate unified semantics for a long time, it needs to have an original working layer that is controllable, transferable, and constrainable.
3. Data warehouse selection: Postgres
The data warehouse of this project is not designed to pursue the largest scale, but to provide a formal analysis base that is stable enough, transparent enough, and easy enough to verify.
Postgres is very suitable as a choice at this stage.
First of all, its integration with Cube is mature, and the subsequent connection cost from the data warehouse to the semantic layer is relatively low.
Secondly, it is very straightforward for dimension tables, fact tables, aggregate tables, indexes, deduplication, debugging SQL, and inspecting results. This is important because the core work here is not extreme performance, but constant verification of "whether the current business caliber is correct."
Again, it gives the entire system a clear layering:
Original working layer: Parquet ↓ Loading layer: staging tables ↓ Analysis layer: mart tables ↓ Semantic layer: Cube models
Common layering methods for enterprise data warehouses are roughly as follows:
Source data → ODS → DWD (detail) → DIM (dimension) → DWS (summary) → ADS/APP (application)
The further forward, the closer it is to the original data, and the further back, the closer it is to business use. For example, ODS is a data layer that "comes into the warehouse first, dropped first", DWD is a detailed fact layer after sorting, DIM is a relatively stable dimensional object layer, and DWS and ADS/APP are closer to the summary and application layer organized according to business caliber.
For business analysis, data querying systems and agents, usually the underlying original layer or cleaning detail layer should not be used directly, but the analysis layer data for business consumption should be used.
Compared with the complete data warehouse, this project has made a lighter implementation: Parquet serves as the original working layer, staging tables is responsible for cleaning, alignment, and type correction after import, and mart tables is responsible for formal modeling for business analysis, which can be used directly by the Cube semantic layer.

Once there is such a layer, the subsequent semantic layer, data querying layer and Agent layer do not need to directly touch the original data files, nor do they need to repeat the cleaning logic in every place.
Why not let the upper layer directly read the data access database? The reason is not that the database cannot be queried, but that the database cannot naturally bear the responsibility of unifying business semantics, because the business will continue to change, and the database layer should remain as stable as possible. The underlying data warehouse should not frequently change tables, structures, and downstream dependencies in order to adapt to every change in business caliber; these are more suitable to be converged in a semantic layer like Cube.
4. Three core tables
The following are the three core tables to be processed in the current project:
dim_productsfact_reviewsfact_product_daily_metrics
The relationship between the three tables is as follows:
Product original data → dim_products Review original data → fact_reviews → fact_product_daily_metrics
Among them, dim_products and fact_reviews are independently sorted out from two types of raw data, product and review, and share the same product_id convention; fact_product_daily_metrics is an analysis layer formed by further aggregating by product and date on top of fact_reviews.
1. dim_products
This table is responsible for answering the most basic question:
In this system, what exactly is a “commodity” and what attributes does it have that can be stably reused?
For example, replace parent_asin with product_id. This is not a perfect answer, but for the current public data set, it is a sufficiently stable, consistent, and reusable commodity primary key selection.
What is precipitated in this table is not only the product title, brand, category and price, but more importantly: it provides unified product granularity and price granularity for the subsequent semantic layer.
2. fact_reviews
This table holds review facts.
Its value is not just to "load comments into the database", but to turn comments into a basic fact table that can be shared by all subsequent analysis layers. Rating, review text, review date, verified purchase, helpful vote, these fields will be used repeatedly in the future.
At the same time, this layer also completes comment deduplication and basic standardization. In other words, the subsequent semantic layer and data querying layer deal with "arranged review facts" instead of temporarily patching dirty data during each query.
3. fact_product_daily_metrics
If the first two tables are defining "objects" and "original events", then this table begins to carry the real analysis semantics.
It aggregates review data by product and date to form:
review_countavg_ratingnegative_review_countnegative_review_ratereview_velocity_7dreview_velocity_30drating_change_30dnegative_rate_change_30d
This step is very important, because it means that many high-frequency data querying problems no longer need to be temporarily derived from comment details every time, but can be built on a formal daily indicator layer.

in other words:
fact_product_daily_metricsIt is not a simple intermediate table, but the first formal carrying layer for subsequent trend analysis, opportunity signals and risk signals.
5. Caliber definition
The "caliber" mentioned here can be simply understood as: how to calculate the same indicator, at what granularity, and how to draw the boundary.
For example:
product_id = parent_asin negative review = rating <= 2 price_band = unknown / <10 / 10-20 / 20-40 / 40-80 / 80+ review_velocity_7d = rolling sum of reviews for the last 7 observation days review_velocity_30d = rolling sum of reviews for the last 30 observation days
These definitions may seem like "low-level implementation details" now, but in fact, they directly determine the behavior of all subsequent layers.
If this layer is not unified first, the subsequent Cube semantic layer, data querying interface, Agent tools, Dashboard charts, and training features will each explain these concepts, and finally return to the state of "everyone can find the data, but no one can tell the caliber."
The caliber set here is used to support the basic definition of data warehouse modeling. After entering the Cube semantic layer in the next article, we will further upgrade these definitions into formal indicators, dimensions, segments, time semantics and unified query contracts.
Conclusion
This article talks about the data layer, focusing on "how to prepare a stable enough base for unified business semantics."
So far, we already have:
Reproducible public data sources
The original working layer managed by the project itself
Formal data warehouse layer
The first batch of reusable product, review and daily indicator models
But just having a data warehouse does not mean having unified business semantics.
The problems to be solved in the next article are:
How should the indicators, dimensions, segments, signals and relationships on the data warehouse be solidified into a set of business semantics that can truly be shared by humans, agents, dashboards and ML?