In the previous article "Ask-Data Technology Route and Selection", we sorted out several mainstream technology routes of Ask-Data and mentioned that: semantic layer is the core infrastructure of enterprise-level Ask-Data.
This article will introduce a typical open source semantic layer framework: Cube Core (https://github.com/cube-js/cube). It should be noted that the name Cube has two meanings in different contexts: in a narrow sense, it refers to the self-hosted open source semantic layer Cube Core; in a broad sense, it can also refer to the complete product system built around Cube Core by Cube Company, including commercial capabilities such as Cube Cloud, Cube Platform, and Agentic Analytics. This article mainly discusses Cube Core, but in order to understand its evolution direction, it will also cover the capabilities in the Cube commercial product system as appropriate.
Cube Core is an open source semantic layer for BI, embedded analytics, and AI Agents. It allows AI and BI tools and applications to initiate queries through the semantic layer instead of directly accessing the underlying data source. This is very critical for Ask-Data; in enterprise-level data querying scenarios, the question is usually not "whether LLM can write SQL", but:
- How is GMV calculated?
- How to define new customers;
- Whether income includes refunds;
- Is this month a natural month or a financial month?
- Can this user see the data of this department?
- Which join path should be taken between multiple tables;
- Whether the result hits the cache and whether it is traceable.
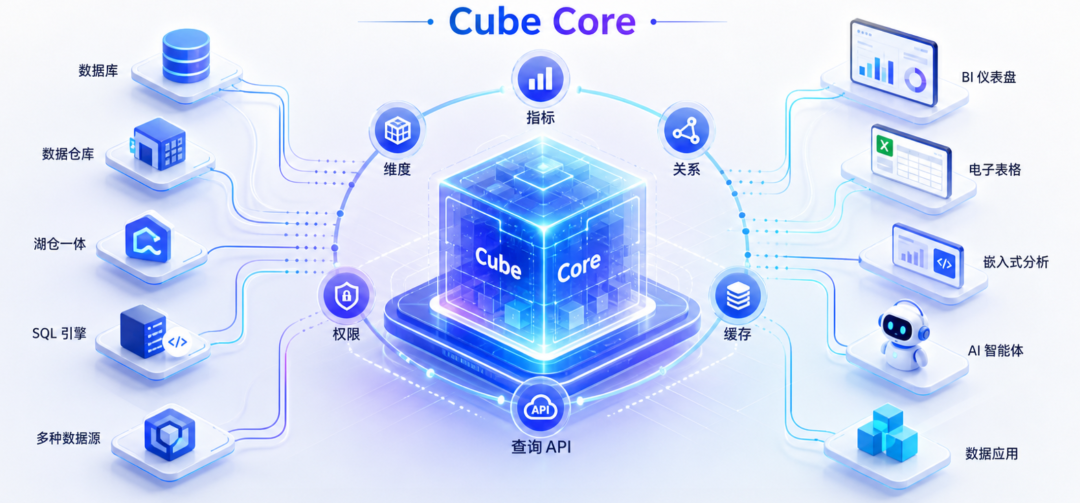
Cube's positioning is to forward these indicator calibers, dimension relationships, permission rules and query acceleration capabilities into the semantic layer, allowing upper-layer BI tools, applications and AI Agents to perform data querying on stable and manageable business semantics objects.
Database / data warehouse / lake warehouse / query engine
↓
Cube semantic layer
- Indicators
- Dimensions
- relation
- Permissions
- cache
- Query interface
↓
BI Tools / Excel / Embedded Analysis / AI Agent / Data ApplicationNext, we first review the development history of Cube to help readers understand why it is suitable for semantic layer and Ask-Data scenarios; and then sort out its core functions and architecture.
The development history of Cube system
Cube originated from the "embedded analysis" and "data application" scenarios.
Cube's history can be traced back to 2016, when Cube's founders Artyom Keydunov and Pavel Tiunov founded a data company called Statsbot, which often dealt with governance issues such as data modeling, indicator calibers, and data assets.
As the business developed, the Statsbot team discovered that data engineers already had many internal data infrastructure tools at the time. However, when software engineers built production-level, customer-visible embedded analysis functions, they lacked tools that could highly customize the front end, support big data scale, and do not require complex data pipelines.
At that time, in many SaaS, operating systems, and customer backends, developers needed to provide users with functions such as reports, indicator panels, trend charts, funnels, retention, and rankings. This scenario is different from traditional BI:
- The front end needs to be highly customized;
- The query must be able to withstand the concurrency of many external users;
- The indicator caliber should be stable;
- Permissions and multi-tenancy should be strict;
- The query cannot be directed to the underlying data warehouse every time;
- Every application team cannot be required to maintain complex data pipelines.
Phase 1: 2019, Cube.js open source
In March 2019, based on their understanding of their own and industry needs, Pavel Tiunov and Artyom Keydunov packaged the core functions into Cube.js and made it open source. It is worth mentioning that Cube.js has been running in the production environments of many companies for more than a year before being open source, and has processed PB-level data sets. Within months after Cube was open sourced, thousands of developers began building applications based on Cube.js.
An important design of early Cube.js wasvisualization-agnostic, that is, the visualization layer is not bound. The official made it clear at the time that they would not reinvent a visualization library, but let Cube.js only be responsible for back-end data query and result processing. The front-end can connect to any component such as Chart.js, D3, React, Vue, etc. This makes Cube.js very suitable for the following scenarios:
- Embed customer reports in SaaS products;
- Customized dashboard in the operation backend;
- analytics portal for external customers;
- Internal data applications;
- Requires an API-first analytics backend.
Phase 2: 2020, from open source project to corporate operation
After Cube.js was open sourced in March 2019, community and production use grew rapidly. In 2020, Cube Dev announced $6.2 million in funding, and at that time Cube.js was already deployed on more than 70,000 servers in enterprises around the world.
At this stage, Cube's positioning is still "modern analysis application infrastructure". The problem it solves is not natural language data querying, but:
- How to uniformly define indicators;
- How queries are exposed through the API;
- How caching and pre-aggregation are managed;
- How to control multi-tenancy and permissions;
- How to enable developers to build data applications faster.
At the same time, Cube Dev also started planning Cube Cloud. Officials said at the time that the core capabilities would continue to be open source, with the server code using Apache 2.0 and the front end using MIT. At the same time, a commercial version of Cube Cloud would be built to help developers deploy, expand and operate Cube.js.
Stage 3: In 2021, Cube Store appears, query performance becomes a key capability
As Cube was used in more production environments, the team discovered that simply converting queries into SQL was not enough. At that time, the bottlenecks of analytical queries were often:
- High user concurrency;
- Large amount of data;
- There are many query dimensions;
- There are many TopN, time trends, and group aggregations;
- The cost and delay of checking the warehouse every time is high.
So Cube launched the Cube Store. Cube Store is Cube's dedicated pre-aggregated storage layer to support high concurrency and low latency queries. When the official released Cube Store GA in 2021, they stated that it is a custom pre-aggregation storage layer for Cube.js. The goal is to allow Cube.js to provide sub-second latency for highly concurrent applications on top of any SQL-compliant database, data warehouse, or query engine.
The structure of Cube Store is roughly as follows:
Cube API
→ hit pre-aggregation
→ Cube Store Router
→ Cube Store Workers
→ Parquet / Blob StorageCube Store uses a distributed query engine architecture: routers are responsible for connections, metadata, query planning and scheduling, workers are responsible for ingestion and parallel execution of queries, and pre-aggregated data is stored in columnar format in local or cloud object storage. Officials also stated that Cube Store is written in Rust and uses open source components such as Parquet, Apache Arrow and DataFusion.
At this stage, Cube began to change from "analysis API framework" to "semantic layer + query acceleration layer". For Ask-Data, this means that the semantic layer is not only responsible for "defining the caliber", but also "allowing query results to be returned quickly in interactive scenarios."
Phase 4: In 2021, Cube Cloud, SQL API, and GraphQL API promote Headless BI
Also in 2021, there are several important changes coming to Cube.
First, Cube Cloud GA. Cube Cloud is a hosted version of Cube, with the goal of eliminating the need for developers to manage Cube's deployment, expansion and contraction, monitoring, query tracking, pre-aggregation refresh, and security configuration. According to the official release, Cube Cloud is a fully managed service for running Cube applications, and provides API instance automatic scaling, caching and pre-aggregation warm-up, GitHub integration, collaborative schema editing, monitoring, query tracking, pre-aggregation management and security capabilities.
Second, Cube publishes SQL API. This change is critical because it allows Cube to no longer just provide a JSON/REST API to the application front-end, but can be connected to BI tools like a database. The official stated clearly in the SQL API release article that Cube can be used as a metrics store to provide consistent metrics for any data consumer and become a headless BI layer.
Third, Cube publishes a GraphQL API. The GraphQL API allows Cube to serve as part of an application's GraphQL layer, providing metrics data to the front end and application. Officials also regard SQL API and GraphQL API as important steps towards a universal, headless analytics layer.
Cube’s route at this stage can be summarized as:
Unified indicator definition
→ Multi-protocol query interface
→ BI/application/front-end can be consumed
→ Headless BIPhase 5: 2022, renamed from Cube.js to Cube
In 2022, Cube.js was officially renamed Cube. Officials explained that this name change, although superficially just a name change, reflects Cube’s evolution from an “open source JavaScript analysis framework” to a headless BI platform.
This name change is very representative. Because it was called Cube.js in the early days, people would think it was a front-end visualization library similar to Chart.js and D3.js. But in fact Cube has become a lower-level data infrastructure:
- Not just JavaScript;
- Contains Cube Store written in Rust;
- Not just application front-end tools;
- Support SQL API, GraphQL API;
- For BI, embedded analytics, indicator layer and semantic layer;
- Start to become a headless BI / semantic layer that is independent of specific BI tools.
Therefore, Cube.js was renamed Cube, which essentially upgraded the product positioning from "JS analysis framework" to "universal semantic layer".
Stage 6: After 2024, Cube will clearly enter the direction of AI semantic layer
After the emergence of large models, companies began to try to let AI directly check data. But using Text2SQL directly will quickly run into problems:
- Don’t know the indicator caliber;
- Don't know the join path;
- Not aware of permissions;
- Don’t know the business alias;
- Don’t know the time scale;
- It is difficult to stably verify the generated SQL;
- The answer to the same question may be different in different tools.
Cube cuts right into this issue.
In 2024, Cube announced the completion of US$25 million in financing, in which Databricks participated in strategic investment. Cube recalled in the article that they launched Cube in 2019 to create a place for unified management of data models, security and caching; by 2024, Cube Cloud has been positioned as a universal semantic layer between data sources and data applications, which can provide the same set of semantics to BI, Excel, embedded analysis and AI agents.
In other words, the value of Cube in the AI era is not just to "write SQL for large models", but to provide a deterministic, manageable, and reusable semantic layer for AI.
Stage 7: In 2025, Cube moves further towards Agentic Analytics
In 2025, Cube released D3, which is data in cube, defining it as an agentic analytics platform built on Cube semantic layer. D3 includes capabilities such as Analytics Chat, Workbooks, Data Apps, and Semantic Modeling, with the goal of allowing AI Agents and humans to collaborate on modeling, exploration, and reporting.
Later, Cube announced Cube Agentic Analytics GA, removed the D3 name, and unified the semantic layer and agentic analytics products under the single brand Cube. The officially described vision is for agents and humans to work together, from modeling to exploration to presentation, while humans retain fine-grained control.
At this point, Cube’s development path has roughly become:
Cube.js open source embedded analysis framework
→ Cube Store query acceleration
→ Cube Cloud hosting platform
→ SQL / GraphQL / REST multi-protocol Headless BI
→ Universal Semantic Layer
→ AI / BI / Embedded Analytics unified semantic layer
→ Agentic AnalyticsCube’s core features
Earlier we introduced the development history of Cube. Next we talk about the core functions of Cube. The functions of Cube can be divided into several layers.
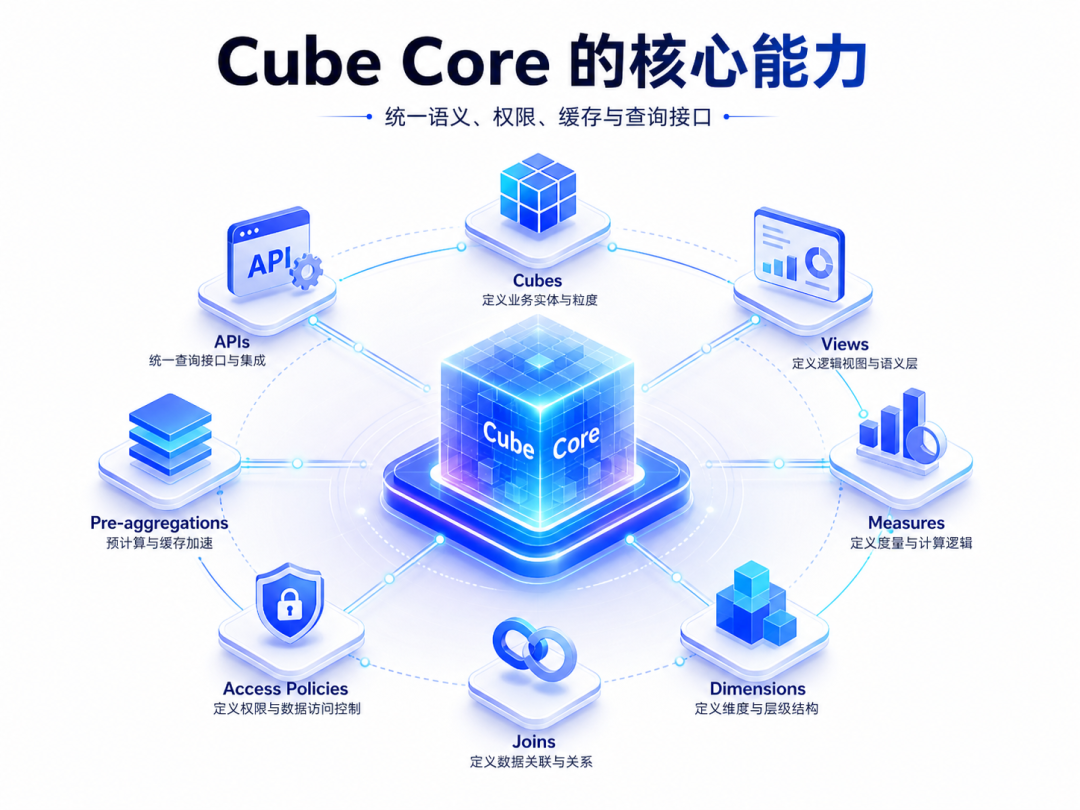
Data modeling: defining business objects, metrics, dimensions and relationships
Cube’s data model is based oncubesas the core. According to Cube's official description, Cube's data model is an entity relationship diagram containing measures and dimensions; in Cube, entities are called cubes, which are essentially data tables with semantic metadata that describe measures, dimensions, and relationships with other cubes.
Typical modeling objects include:
- Cube: Business entities, such as orders, users, products, payments;
- View: Data product view for consumers.
- Measure: Indicators, such as number of orders, sales, GMV, conversion rate;
- Dimension: Dimensions, such as channels, regions, products, user types;
- Segment: Common conditions, such as paid orders, active users, and new customers;
- Join: Entity relationship, such as order-related user, order-related product;
It can be simply understood as:
Underlying table: orders
business objects: orders
Indicators: number of orders, payment amount, refund amount
Dimensions: order status, channel, city, creation time
Relationship: order → user, order → product, order → storeThe new version of Cube's documentation distinguishes Cubes and Views more clearly: Cubes represent business entities such as customers, line items, and orders, and define the relationship between measures, dimensions, and entities; Views are located on top of the data graph of cubes and serve as the final data product for the interaction between AI agents, BI users, and applications.
This means that the Cube is not just a "field alias table", but a business semantics graph.
Query interface: REST, GraphQL, SQL, DAX, MCP
An important feature of Cube is API-first/headless.
It does not only serve a certain BI front end, but provides a variety of standard protocols so that different consumers can access it.
The Core Data APIs listed in the official document include SQL, DAX, REST JSON and GraphQL; the document also mentions that AI assistants (commercialization) can use MCP Server, Power BI can use DAX API, and embedded analysis and real-time analysis can use REST or GraphQL API.
This is also the basis for Cube to expand from embedded analysis to BI and AI.
Query Compilation: Generating underlying SQL from semantic queries
Cube's queries do not directly expose the underlying SQL table, but expose semantic objects.
In the SQL API, Cube maps each cube or view into a table, and maps measures, dimensions, and segments into columns. Queryers can query Cube just like ordinary tables, but the underlying calculations are still generated by Cube based on the semantic model. The official documentation also states that measure can be passed through specialMEASUREAggregate function reference.
This is important for Ask-Data.
Because of this, LLM faces clear semantic layer objects:
orders.count
orders.total_revenue
orders.created_at
customers.region
products.categoryinstead of:
ods_order_detail_v3
dw_user_dim_202404
fact_payment_refund_dailyThe semantic layer hides the underlying complex SQL, table structure and calculation logic, allowing the upper layer to only face stable business objects.
Caching and pre-aggregation: making data querying not only “answerable” but also “answerable”
If the enterprise data querying system directly enters the data warehouse every time, it will encounter two problems:
- High latency and poor user experience;
- The cost is high, especially when cloud data warehouses charge per query.
One of Cube's core capabilities is caching and pre-aggregation.
Cube documentation states that Cube achieves aggregate awareness through pre-aggregations. The data team defines rollup tables in the model, and Cube builds and refreshes these pre-aggregations in the background, and stores the results in the Cube Store; when a query comes, if there is available and fresh pre-aggregation, Cube will use the pre-aggregation service to query, thereby reducing latency and data warehouse costs.
A typical structure is:
Original data sheet
→ Cube background builds pre-aggregation
→ Cube Store storage rollup
→ Priority hits pre-aggregation when user queries
→ Check the underlying data warehouse if necessaryThis makes Cube not only a semantic layer, but also a query acceleration layer.
Permission management: row level, member level, contextual permissions
After Ask-Data enters the enterprise scenario, permissions are an unavoidable issue.
User asked:
What is the sales volume of each region this month?
The system must know:
- Which department the user belongs to;
- Can you see all areas?
- Can I see the amount field;
- Whether you can only see the customers you are responsible for;
- Whether the returned result needs to be desensitized;
- Whether the AI Agent also respects the same permissions.
Cube's Access Policies can control row-level security and member-level security on cubes and views, that is, restrict which rows, indicators or dimensions users can see.
The new version of Cube documentation further emphasizes that after access control is centralized in the semantic layer, AI agents, BI tools, and custom applications must all pass the same governed checkpoint to prevent agents from inadvertently exposing sensitive data or violating security policies.
This is also one of the advantages of semantic layer compared to direct Text2SQL: instead of relying on AI to understand and comply with permission rules on its own, all queries go through a deterministic permission control layer.
Of course, for companies that have already established a complete BI or data governance system, permission control may have been partially implemented in the existing architecture. The value of Cube lies more in the unified acceptance of these rules.
Cube's architecture
The logical architecture of Cube can be summarized as:
data source
- Snowflake
- BigQuery
- Databricks
- Postgres
- MySQL
- ClickHouse
- Trino / Presto
- Other SQL data sources
↓
Cube Semantic Layer
- Cubes
- Views
- Measures
- Dimensions
- Joins
- Segments
- Access Policies
- Pre-aggregations
↓
Cube APIs
- REST
- GraphQL
- SQL
- DAX
- MCP
- SDK
↓
Consumer side
- BI tools
- Excel / Sheets
- Embedded analytics
- AI Agent
- Analytics Chat
- Data applicationsAccording to the official architecture documentation, a typical Cube Core production deployment includes one or more API instances, a Refresh Worker, and a Cube Store cluster. API instances handle external API requests and query the Cube Store or connected data sources; the Refresh Worker builds and refreshes pre-aggregations in the background; the Cube Store receives the pre-aggregations built by the Refresh Worker and responds to queries from the API instances.
in:
- API Instances: Responsible for receiving queries, authenticating, compiling queries, and returning results;
- Refresh Worker: Responsible for refreshing pre-aggregation, maintaining refresh keys, and invalidating cache;
- Cube Store: Responsible for storing and querying pre-aggregated data;
- Router / Workers: Distributed query component inside Cube Store;
- Blob Storage: Save columnar pre-aggregated data.
Simply put, Cube's production architecture is not a lightweight SQL wrapper, but an analysis service layer with semantic model, permission control, cache orchestration and distributed pre-aggregation storage.
What scenarios is Cube suitable for?
Cube is more suitable for the following scenarios:
| scene | Is it suitable for Cube? | reason |
|---|---|---|
| Single table, small wide table, temporary data querying | Not necessarily required | Text2SQL may be faster |
| One-time analysis and exploration | Not necessarily suitable | Modeling costs may outweigh benefits |
| SaaS product embedded customer reporting | Very suitable | Requires API, caching, multi-tenancy, permissions |
| Enterprise unified indicator layer | Very suitable | Need to unify metrics and dimensions |
| Indicators shared by multiple BI tools | Very suitable | SQL API / Semantic Layer Sync reusable semantics |
| AgentAsk-Data | Very suitable | AI queries the semantic layer instead of directly checking the database |
| Cross-departmental complex indicator governance | Suitable, but requires modeling investment | Requires a complete semantic model and permissions management |
| Enterprises without data governance foundation | It works, but it doesn’t magically solve dirty data | Upstream data quality is key |
What Cube can’t solve
Cube cannot automatically repair upstream dirty data, cannot replace data warehouse modeling, cannot automatically unify the organizational consensus on indicators within the company, and cannot independently complete the natural language data querying experience. It solves the infrastructure problems of "unified semantics, unified query, unified permissions, and unified acceleration". The premise for introducing Cube is that enterprises are willing to invest in semantic modeling.
Conclusion
The essence of Cube is not a "tool for writing SQL for large models", but an infrastructure for productizing enterprise data semantics.
Its development path is clear:
Embedded analytics framework
→ Analysis API
→ Pre-aggregation and query acceleration
→ Headless BI
→ Universal Semantic Layer
→ AI / Agentic AnalyticsFor Ask-Data, Cube represents a more enterprise-level and more manageable technology route:
Rather than letting LLM directly face the database
Instead, let LLM face the semantic layer
Instead of temporarily generating the caliber every time
Instead, govern indicators, dimensions, relationships, and permissions in advance
It’s not just about being able to answer
Instead, we pursue controllability, trustworthiness, reusability, traceability, and scalability.It can be understood this way: lightweight data querying can start with Text2SQL; but if the goal is enterprise-level trusted data querying, especially in scenarios such as Agent and Agentic AI, semantic layer products such as Cube are very typical technology choices.