智能问数系统进入研发和迭代后,会面临一个重要问题:系统每次调整模型、Prompt、语义层或查询逻辑后,之前能正确回答的问题,是否还能继续正确回答?
这就是回归测试要解决的问题,也是本篇文章要讲的内容。
智能问数系统回归测试的核心目标,是保障系统在持续迭代中的稳定性。它不是简单维护一批固定答案,而是把高频、关键、容易出错的问题整理成 Golden Questions,用来反复验证系统是否发生退化:问题有没有理解错,查询有没有生成错,结果是否合理,回答是否清楚可审计。
这些问题通常来自真实业务场景。例如指标口径、时间范围、权限控制、结果追溯、动态数据等。它们会成为回归测试用例的一部分。回归测试的重点不是把所有业务问题一次性解决,而是建立一套可持续运行的验证机制。
智能问数系统的回归测试不能简单写成:
question → answer因为智能问数不是普通问答。它至少包含下面几步:
自然语言问题
↓
生成查询
↓
执行查询
↓
返回结果
↓
组织回答如果只维护一个固定自然语言答案,很快会失效。业务数据是动态变化的,今天的销售额、退款率、评论数,明天可能就变了。同时只要指标口径和结果正确,回答方式可以不同。
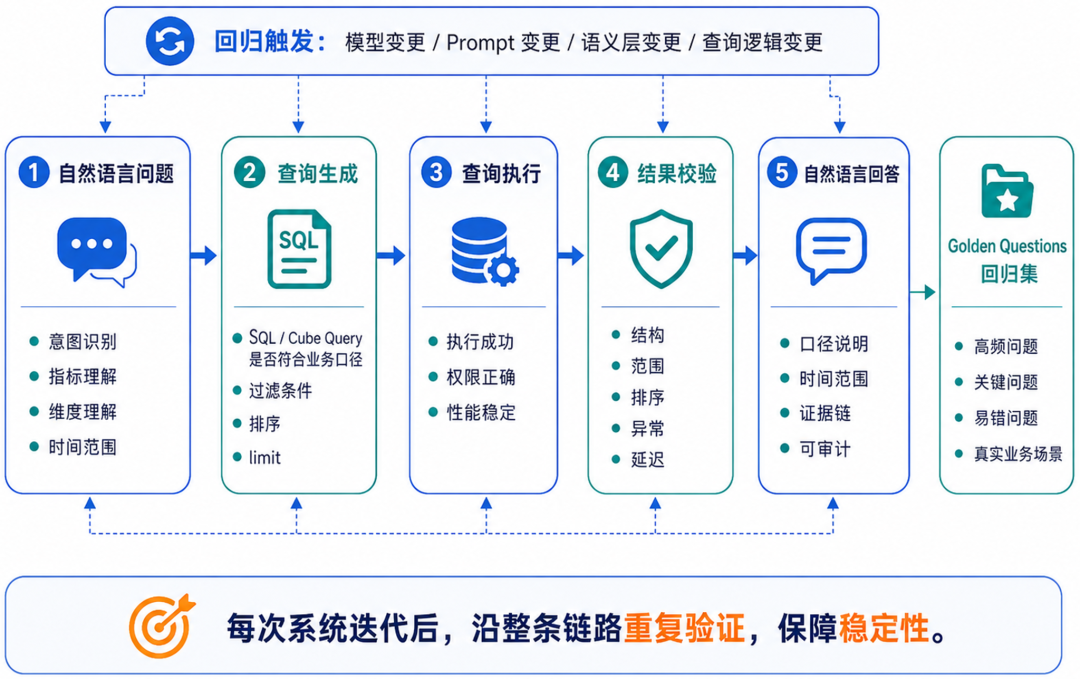
因此,智能问数系统回归测试的目标,不是维护一套固定答案,而是要保证四件事:
问题是否理解正确
查询是否生成正确
结果是否合理可信
回答是否清楚可审计针对智能问数常见的 Text2SQL 与 IR(如Cube)Query 两种路线,回归测试的重点也不同。
一、Text2SQL 路线:回归测试重点在 SQL 是否符合业务口径
Text2SQL 的链路是:
自然语言 → SQL → 数据库 → 结果 → 回答这条路线最直接,但评估也比较复杂。因为 SQL 直接面对物理表,容易出现选错表、选错字段、漏掉过滤条件、Join 错误等问题。
例如用户问:
本月销售额是多少?
模型可能生成:
SELECT SUM(amount)
FROM orders
WHERE created_at >= '2026-06-01';这条 SQL 可以正常执行,但业务上不一定正确。
因为“销售额”到底应该用 amount、paid_amount,还是 net_amount?时间字段应该用 created_at,还是 paid_at?是否要排除测试订单?是否只统计已支付订单?
这些都属于业务口径问题。
因此,Text2SQL 的回归测试不能只看 SQL 是否能执行,还要看这条 SQL 是否符合业务定义。
这里容易想到一个办法:既然业务口径这么重要,那是不是只要维护一条准确的参考 SQL,然后把模型生成的 SQL 和参考 SQL 做对比就可以了?
参考 SQL 确实很有价值,可以作为业务口径的基准。但在回归测试里,不建议直接做 SQL 字符串级比对。
原因是,同一个业务查询可能有多种正确写法。模型可以使用不同的别名、CTE、子查询、宽表或预聚合表,只要最终业务口径一致,就不应该判错。
也就是说,参考 SQL 是重要基准,但测试重点不是让模型 SQL 长得和参考 SQL 一样,而是确认它是否表达了同一个业务定义。
例如:
SELECT SUM(paid_amount)
FROM fact_orders
WHERE status = 'paid';和:
SELECT SUM(o.paid_amount)
FROM fact_orders o
WHERE o.status = 'paid';字符串不同,但含义基本一致。
有时还可能使用 CTE、子查询、宽表、预聚合表。只要口径一致,写法不同不一定是错的。
如果非要基于 SQL 对比,更合适的做法是执行结果对比,而不是做字符串级精确匹配。
例如测试时可以执行两条 SQL:
模型生成 SQL → 得到结果 A
参考 SQL → 得到结果 B
比较 A 和 B这种方式比维护固定答案更适合动态数据。因为数据每天都在变化,但两条 SQL 都在当前数据上执行。只要结果一致,就说明生成 SQL 通过了当前数据集下的结果校验。
二、 SQL AST 检查
参考 SQL 执行结果对比很有用,但也有局限。
第一,它只能告诉你结果是否一致,不一定能告诉你错在哪里。
第二,如果当前数据没有覆盖边界情况,错误 SQL 也可能碰巧算出一样的结果。
例如,正确口径应该用 paid_at,模型却用了 created_at。如果当前数据里所有订单都是当天下单当天支付,两条 SQL 结果可能一样。
再比如,正确口径应该排除测试订单,模型却没有加 is_test = false。如果当前测试订单刚好没有金额,结果也可能一样。
所以,更建议的做法是 SQL 结构检查。
可以用 SQL Parser 将 SQL 解析成 AST,再从 AST 中抽取结构信息,例如:
使用了哪些表
使用了哪些字段
用了哪些聚合函数
where 条件是什么
join 条件是什么
group by 维度是什么
order by 字段是什么
limit 是多少然后把这些结构信息和指标定义进行比对。
例如指标定义写清楚:
metric_id: sales_amount
display_name: 销售额
required_table: fact_orders
amount_column: paid_amount
time_field: paid_at
aggregation: sum
required_filters:
- status = paid
- is_test = false模型生成 SQL 后,通过 AST 抽取出它实际用了哪些字段和过滤条件。
如果用了 amount,就能发现字段不符合口径。
如果用了 created_at,就能发现时间口径不对。
如果漏了 status = paid,就能发现过滤条件不完整。
这里的数据字典和指标定义,不是为了让 AST 理解业务,而是为了把业务口径变成可检查的规则。
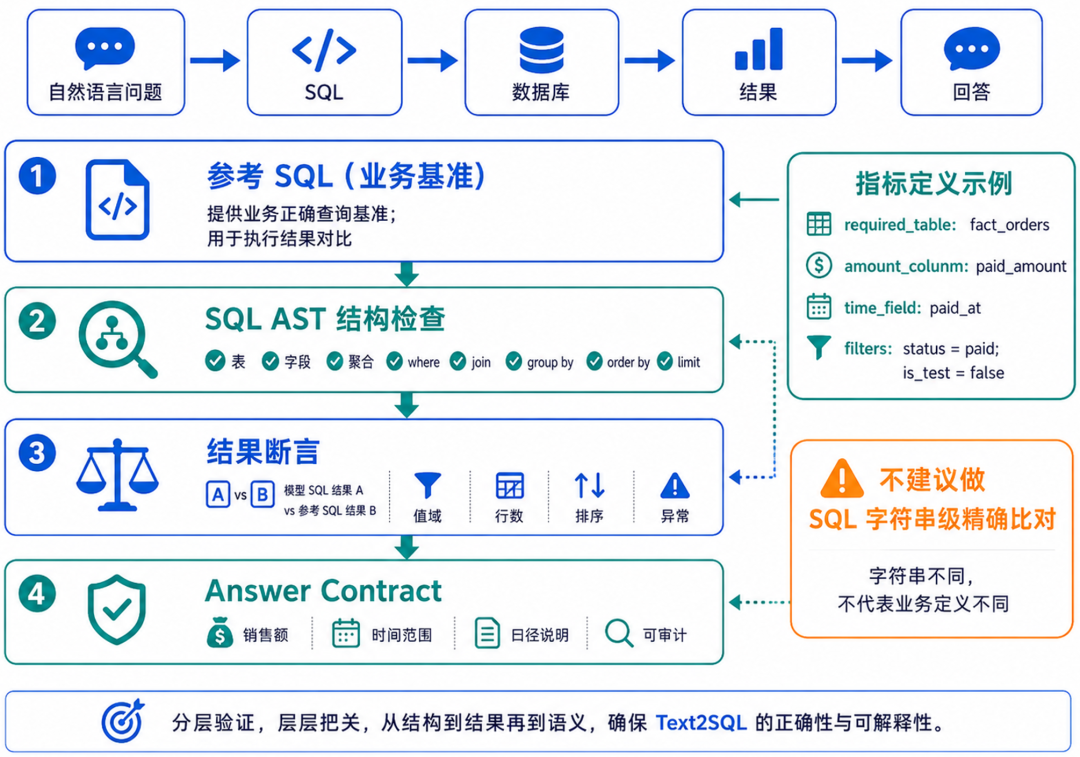
三、Text2SQL 回归测试用例可以这样写
一个 Text2SQL 回归测试用例可以设计成这样:
id: gq_sales_001
question: 本月销售额是多少?
reference_sql:
sql: |
SELECT SUM(paid_amount) AS sales_amount
FROM fact_orders
WHERE paid_at >= :month_start
AND paid_at < :month_end
AND status = 'paid'
AND is_test = false
expected_sql_structure:
required_tables:
- fact_orders
required_columns:
- fact_orders.paid_amount
- fact_orders.paid_at
- fact_orders.status
- fact_orders.is_test
required_aggregations:
- function: sum
column: fact_orders.paid_amount
required_filters:
- field: fact_orders.status
operator: equals
value: paid
- field: fact_orders.is_test
operator: equals
value: false
forbidden_columns:
- fact_orders.amount
- fact_orders.net_amount
forbidden_patterns:
- select_star
result_assertions:
compare_with_reference_sql: true
value_constraints:
sales_amount:
min: 0
answer_contract:
must_include:
- 销售额
- 时间范围
- 口径说明这里有三类检查。
第一,参考 SQL 用来提供业务正确的查询基准。
第二,SQL AST 结构检查用来确认模型生成 SQL 是否用了正确的表、字段、聚合和过滤条件。
第三,结果断言用来确认最终结果是否合理。
这样比单纯比较 SQL 字符串更可靠。
不过,这套方式也有成本。因为它直接依赖物理表和字段,一旦数仓表结构变化、字段调整、宽表拆分、指标表重构,测试用例也要跟着改。此外,还要引入 AST 的处理和判断逻辑。
这也是 Text2SQL 路线在企业长期落地时会逐渐变重的原因之一。
四、Cube Query 路线:回归测试围绕语义查询来做
如果智能问数系统使用 IR,例如以 Cube 作为语义层,回归测试可以相对轻一些。
因为 Cube 天然已经把很多业务语义结构化了。Cube Query 中会明确表达:
查什么指标:measures
按什么维度看:dimensions
过滤什么条件:filters
看什么时间范围:timeDimensions
怎么排序:order
取多少条:limit也就是说,Cube Query 本身比 SQL 更接近业务语义。
在这种情况下,系统主链路可以是:
自然语言问题
↓
Cube Query
↓
Cube 执行
↓
结果
↓
自然语言回答这时测试重点,不再是检查 SQL 里用了哪个物理字段,而是检查生成的 Cube Query 是否包含正确的指标、维度、过滤条件、时间范围、排序和 limit。
五、不完整比对 Cube Query,比对 Query Contract
在具体落地时,直接基于 Cube Query 做回归测试,也不建议做完整 JSON 精确比对。
因为生成的 Cube Query 可能多带一个辅助指标,字段顺序可能不同,过滤条件顺序也可能不同。完整比对容易产生误报。
更实用的方式是定义 Cube Query Contract,也就是只检查这个问题必须满足的查询约束。
例如用户问:
最近 90 天 Beauty 类目里,差评率最高的 10 个商品是什么?
这个问题的 Query Contract 可以是:
必须查差评率
必须按商品维度返回
必须过滤 Beauty 类目
必须限定最近 90 天
必须按差评率倒序
必须返回 Top 10对应的回归测试用例可以写成:
id: gq_review_001
question:
main: 最近 90 天 Beauty 类目里,差评率最高的 10 个商品是什么?
variants:
- Beauty 类目最近 90 天差评率最高的商品有哪些?
- 找出近 90 天 Beauty 类目差评率 Top 10 商品
expected_cube_query_contract:
required_measures:
- Reviews.negativeReviewRate
should_include_measures:
- Reviews.reviewCount
- Reviews.negativeReviewCount
required_dimensions:
- Products.productId
- Products.title
required_filters:
- member: Products.category
operator: equals
values:
- Beauty
required_time_dimensions:
- member: Reviews.reviewDate
date_range: last_90_days
required_order:
member: Reviews.negativeReviewRate
direction: desc
required_limit: 10
result_assertions:
required_fields:
- product_id
- title
- negative_review_rate
row_count:
max: 10
value_constraints:
negative_review_rate:
min: 0
max: 1
sort:
field: negative_review_rate
direction: desc
answer_contract:
must_include:
- 时间范围
- 类目
- 差评率口径
- Top 10 商品列表
should_include:
- 评论数
- 差评数
- 数据限制说明这里的回归测试用例分三层:
Cube Query Contract:检查查询是否符合问题意图
Result Assertions:检查结果结构和数值范围是否合理
Answer Contract:检查回答是否包含必要解释这套方式比维护标准 SQL 更轻,也更适合基于语义层的智能问数系统。
六、Cube Query 回归测试需要先做规范化
使用 Query Contract,不建议直接拿原始 Cube Query 做比较。
测试前最好先做 normalize,把等价但写法不同的 Query 归一化,这样可以减少对比时的不确定性。
例如:
数组顺序统一
字段顺序统一
默认 limit 补齐
时间表达统一
过滤条件顺序统一
order 格式统一
member alias 归一推荐流程是:
生成 Cube Query
↓
normalize
↓
匹配 Query Contract
↓
执行 Cube Query
↓
校验 Result Assertions
↓
校验 Answer Contract这样可以避免因为 JSON 顺序、默认参数、时间表达不同导致测试误报。
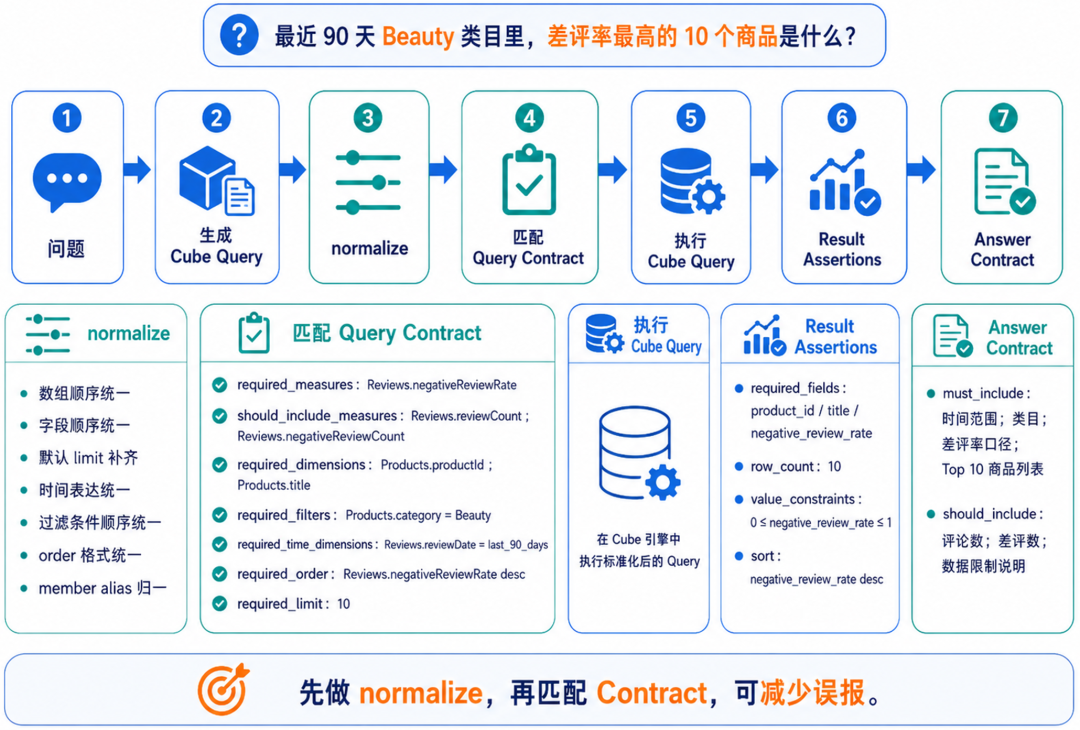
七、动态数据的测试
无论是 Text2SQL 还是 Cube Query,都会遇到动态数据问题。
如果每个回归测试用例都要求固定答案,例如“本月销售额必须等于 123 万”,测试很快会失效。
所以,回归测试可以分成两类。
第一类是固定快照测试。
也就是准备一份固定数据,固定时间上下文,固定语义层版本,固定权限上下文。
这类测试适合做回归,可以校验精确值。
例如:
expected_result:
exact:
sales_amount: 123456.78第二类是动态线上测试。
线上数据每天变化,不适合检查“答案必须等于某个固定值”。
除了上文所说的和参考 SQL 进行执行结果对比,还可以进行结构检查,例如:
live_assertions:
required_fields:
- product_id
- negative_review_rate
row_count:
min: 1
max: 10
value_constraints:
negative_review_rate:
min: 0
max: 1
latency_ms:
max: 5000一句话:
固定快照测精确值,动态线上测结构、范围、权限、排序、延迟和异常。
这样既能保证回归稳定,又不会因为数据变化导致测试频繁失效。
八、不要一开始把回归测试做得太重
智能问数回归测试很重要,但不能一开始就做成大工程。
如果每个问题都维护标准 SQL、标准 Cube Query、标准自然语言答案、标准结果值,团队很快会维护不动。
更实际的做法是分阶段。
第一阶段,MVP 只维护:
question
query contract
result assertions这已经能发现很多核心错误,比如指标选错、维度漏掉、时间范围错、排序错、结果结构错。
第二阶段,试点时增加:
answer contract
permission checks这时开始检查回答是否说明口径,是否返回证据链,不同角色是否遵守权限。
第三阶段,生产后再增加:
固定快照精确值
多角色权限测试
模糊问题追问测试
语义层版本回归
性能测试不要一开始就做生产级回归测试体系。
先把 30 个高频问题跑通,比设计一套庞大但没人维护的测试平台更重要。
九、Text2SQL 与 Cube Query 路线的对比
| 维度 | Text2SQL | Cube Query |
|---|---|---|
| 核心评估对象 | SQL 结构和执行结果 | Cube Query Contract 和执行结果 |
| 是否需要 AST | 建议需要 | 通常不需要 SQL AST |
| 是否绑定物理表 | 强绑定 | 绑定语义层 |
| 主要维护对象 | 表、字段、Join、过滤条件 | measure、dimension、filter、timeDimension |
| 参考 SQL | 有价值,可用于结果对比 | 一般不需要 |
| SQL 字符串比对 | 不建议 | 不适用 |
| 自然语言答案 | 做结构检查,不逐字匹配 | 做结构检查,不逐字匹配 |
| 动态数据处理 | 快照测试 + 动态断言 | 快照测试 + 动态断言 |
| 适合 Agent / ML 复用 | 较弱 | 更强 |
| 落地复杂度 | 较高 | 相对较低 |
结语
智能问数回归测试的目的,不是维护一套形式上完美的标准答案,而是用可维护的方式保证系统可靠。
如果走 Text2SQL 路线,参考 SQL 很有价值,但不建议做 SQL 字符串级比对。更稳妥的方式,是结合参考 SQL 结果对比、SQL AST 结构检查和结果断言,确认生成 SQL 是否符合业务口径。
如果走 Cube Query 路线,可以直接把 Cube Query 作为核心评估对象。第一阶段不需要引入额外复杂抽象,只要围绕 Cube Query Contract、Result Assertions 和 Answer Contract 建立回归测试,就能覆盖大部分核心问题。
智能问数系统的回归测试最终要回答的是:
问题是否理解对,查询是否生成对,结果是否可信,回答是否可审计。