上一篇《语义原生智能问数系统落地实现(一):从亚马逊选品与竞品评论开始》讲清楚了这个项目的背景、定位和整体架构。
这一篇开始进入真正的实现问题:
如果要把这样一个系统搭出来,公开数据应该如何被整理成一套可分析、可复用、可被语义层承载的数据模型?
这一篇对应整个系列的第二步:先把公开数据整理成可以长期复用的正式数据底座,再往上谈语义层、问数层和 Agent 复用。
本篇讲得相对细一点,希望即使不了解数仓的读者,通过此篇,能先对数据仓库以及“原始数据怎么进入正式分析流程”建立一个完整直观的认识,后面再看语义层和智能问数层时不会悬空。
一、公开数据选择
如之前所述,这个项目要验证的是:
在一个边界清楚、语义清楚、结果容易验证的数据场景里,统一语义层驱动的问数系统能不能成立。
所以更合适的做法,是选择一个公开可得、样本足够、分析问题也足够真实的起点。Amazon Reviews 2023 就满足这个条件。
这个数据集本身足够大,包含评论、评分、商品元数据、价格、帮助度投票等结构化信息,也包含评论正文、描述等非结构化文本。它既能支撑基础指标分析,也为后续评论语义增强、痛点聚类、机会评分等能力预留了空间。
Hugging Face 数据集下载地址:https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023
同时完整的 Amazon Reviews 2023 数据集数据量也过大 ,我们只选择 All_Beauty 这个子集。
这个子集数据集大小说明:
All_Beauty reviews: 701,528 All_Beauty items: 112,590 本地原始缓存目录合计: 约 1.01 GB - raw_review_All_Beauty: 526.39 MB - raw_meta_All_Beauty: 486.24 MB 项目导出的 Parquet 合计: 约 198.66 MB - all_beauty_reviews.parquet: 144.56 MB - all_beauty_meta.parquet: 54.10 MB
这组数据的规模可以满足在一台普通开发机上进行验证。
子集包含下面维度的数据信息:
哪些价格带最近评论增长更快? 哪些商品需求上来了,但满意度不高? 高帮助度差评主要集中在哪些商品? 哪些商品有增长,但质量风险也在上升?
二、原始工作层落成 Parquet
Parquet 是 Apache Parquet,一种面向分析场景的列式数据文件格式。可以把它理解成“带明确 schema、适合批量读取和后续分析处理的结构化数据文件”,介于下载得到的原始缓存和正式数仓表之间。
很多项目会直接沿用下载工具产生的缓存目录,或者把原始 JSON、Arrow、JSONL 当作长期输入层。对这个项目来说,关键不只是“数据能不能读出来”,而是“系统有没有一层自己管理的数据输入契约”。
Parquet 在这里的价值主要有三点:schema 明确,方便字段映射和类型检查;列式存储更适合后续筛字段、聚合和导入数仓;它还提供了一层项目自己管理的原始数据边界,后续扩展类目或迁移数仓时都更稳定。
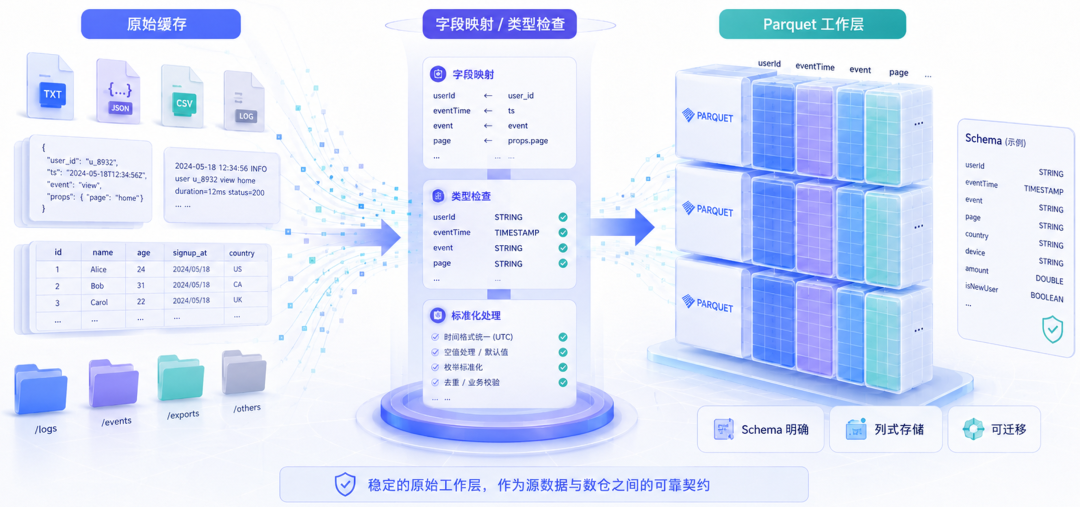
所以这里的关键并不是“Parquet 技术上更高级”,而是:
当一个系统想长期沉淀统一语义时,它需要先有一层自己可控、可迁移、可约束的原始工作层。
三、数仓选择:Postgres
这个项目的数据仓库不是为了追求最大规模,而是为了提供一层足够稳定、足够透明、足够容易验证的正式分析底座。
Postgres 很适合作为这个阶段的选择。
首先,它和 Cube 的集成成熟,后续从数仓到语义层的连接成本比较低。
其次,它对维表、事实表、聚合表、索引、去重、调试 SQL、检查结果都非常直接。这一点很重要,因为这里的核心工作不是极限性能,而是不断验证“当前业务口径是否正确”。
再次,它让整个系统有一个清楚的分层:
原始工作层:Parquet ↓ 装载层:staging tables ↓ 分析层:mart tables ↓ 语义层:Cube models
企业数据仓库常见的分层方式大致是:
源数据 → ODS → DWD(明细)→ DIM(维度)→ DWS(汇总)→ ADS/APP(应用)
越往前越贴近原始数据,越往后越贴近业务使用。像 ODS 是“刚进仓、先落下来”的数据层,DWD 是整理后的明细事实层,DIM 是相对稳定的维度对象层,DWS 和 ADS/APP 则更接近按业务口径组织好的汇总和应用层。
对业务分析、问数系统和智能体来说,通常不应该直接使用底层原始层或清洗明细层,而应该使用面向业务消费的分析层数据。
相对完整数据仓库,这个项目做了一个更轻量的实现:Parquet 作为原始工作层,staging tables 负责导入后的清洗和对齐、类型修正,mart tables 负责面向业务分析的正式建模,供 Cube 语义层直接使用。

一旦有了这样的分层,后面的语义层、问数层和 Agent 层就不需要直接碰原始数据文件,也不需要在每个地方重复清洗逻辑。
为什么不让上层直接去读取数据库?原因不是数据库不能查,而是数据库不能天然承担统一业务语义的收口,因为业务会持续变化,而数据库层应该尽量保持稳定。底层数仓不应该为了适配每一次业务口径变化,就频繁改表、改结构、改下游依赖;这些更适合收敛在 Cube 这样的语义层里。
四、三张核心表
下面是当前项目要处理的三张核心表:
dim_productsfact_reviewsfact_product_daily_metrics
三张表关系如下:
商品原始数据 → dim_products 评论原始数据 → fact_reviews → fact_product_daily_metrics
其中,dim_products 和 fact_reviews 分别从商品、评论两类原始数据独立整理出来,共享同一个 product_id 约定;fact_product_daily_metrics 是在 fact_reviews 之上,按商品和日期进一步聚合形成的分析层。
1. dim_products
这张表负责回答一个最基本的问题:
在这个系统里,“商品”到底是什么,它有哪些可以被稳定复用的属性?
例如把 parent_asin 作为 product_id。这不是完美答案,但对于当前公开数据集来说,是一个足够稳定、足够一致、足够方便复用的商品主键选择。
这张表里沉淀下来的,不只是商品标题、品牌、类目和价格,更关键的是:它给后面的语义层提供了统一的商品粒度和价格带粒度。
2. fact_reviews
这张表保存评论事实。
它的价值不只是“把评论装进数据库”,而是把评论变成后续所有分析层都能共享的基础事实表。评分、评论正文、评论日期、是否 verified purchase、helpful vote,这些字段都会在后续被反复使用。
同时,这一层还完成了评论去重和基础规范化。也就是说,后面的语义层和问数层面对的是“已经整理好的评论事实”,而不是还要在每次查询时临时修补脏数据。
3. fact_product_daily_metrics
如果说前两张表是在定义“对象”和“原始事件”,那么这张表开始承载真正的分析语义。
它把评论数据按商品和日期聚合起来,形成:
review_countavg_ratingnegative_review_countnegative_review_ratereview_velocity_7dreview_velocity_30drating_change_30dnegative_rate_change_30d
这一步非常重要,因为它意味着后面很多高频问数问题已经不需要每次从评论明细临时推算,而是可以建立在一个正式的日指标层之上。

换句话说:
fact_product_daily_metrics不是简单的中间表,而是后续趋势分析、机会信号和风险信号的第一个正式承载层。
五、口径定义
这里说的“口径”,可以先简单理解成:同一个指标到底怎么算、按什么粒度算、边界怎么划。
例如:
product_id = parent_asin negative review = rating <= 2 price_band = unknown / <10 / 10-20 / 20-40 / 40-80 / 80+ review_velocity_7d = 最近 7 个观测日的评论滚动和 review_velocity_30d = 最近 30 个观测日的评论滚动和
这些定义现在看起来像是“底层实现细节”,但实际上,它们会直接决定后面所有层的行为。
如果这一层不先统一,后面的 Cube 语义层、问数接口、Agent 工具、Dashboard 图表和训练特征就会各自解释这些概念,最后重新回到“每个人都能查到数据,但谁也说不清口径”的状态。
这里定的口径,用来支撑数仓建模的基础定义。下一篇进入 Cube 语义层之后,会进一步把这些定义提升为正式的指标、维度、segments、时间语义和统一查询契约。
结语
这一篇讲的是数据层,关注的是“怎么为统一业务语义准备一层足够稳定的底座”。
到这里,我们已经有了:
可复现的公开数据源
项目自己管理的原始工作层
正式数仓层
第一批可复用的商品、评论和日指标模型
但仅仅有了数仓,还不等于有了统一业务语义。
下一篇要解决的问题是:
数仓之上的指标、维度、segments、信号和关系,应该如何被固化成一套真正可被人类、Agent、Dashboard 和 ML 共享的业务语义?