前面讲了语义原生智能问数系统的背景和数仓,上一篇讲了为什么应该把业务对象、指标口径、segments 等固化成可以被人类、智能体、算法脚本一致调用的统一语义层。
本篇开始讲如何基于统一语义层进行查询,这一篇先聚焦它的第一个消费入口:
人类的自然语言问数,如何稳定映射到这套语义上?
很多智能问数项目在这个位置,会把 schema、业务指标定义、公式和概念一起告诉模型,让它生成查询 SQL。但当前项目采取了一个更工程化的办法(下文会详细介绍原因):
不让模型自由生成 SQL,而是先把自然语言问题收敛成一层受控的查询中间表示(IR);在当前实现里,这层 IR 具体采用的是 Cube Query。
这里说的“受控”,不是让模型临场决定最终怎么查,而是系统先定义好可用的业务对象、指标、维度、过滤条件、时间语义和排序方式,再把自然语言问题映射成一套有限且可校验的查询结构。
举个例子,对于问题:
最近 90 天 Beauty 类目里,哪些价格带评论增长最快?
系统把它拆解成受控 IR 所需的几个关键部分:使用哪个业务对象、看哪个指标、按哪个维度分析、带什么过滤条件、采用什么时间语义、按什么方式排序。模型真正要做的,不是发明查询,而是把这句自然语言映射到这套已经定义好的查询结构里。
这一篇对应整个系列的第四步:让“统一语义”真正变成“可被消费的问数接口”,并且在这个阶段优先保证稳定、可解释和可验证。
一、为什么不直接生成 SQL
提到“自然语言问数”,不少人默认会选择使用 NL2SQL。一种常见的观点是:只要把业务指标定义、公式和概念等语义层知识告诉模型,模型就可以写出和受控 IR 等价的 SQL。
这种考虑忽略了一点:即便把业务指标和公式告诉模型,如果最终执行层是开放的,系统还是缺少可校验的边界。
只要最终还是由模型自己决定具体查询结构,它就仍然可能在业务对象选择、时间窗口、过滤条件、聚合粒度、相近指标取舍和排序方式这些地方做临场判断。而如果再使用 AST(抽象语法树,如sqlglot包)从 SQL 反向解析结构化关系,获取可校验的结构并进行校验,这中间过程相较于直接生成受控 IR,会麻烦太多。
所以当前项目在这里要解决的,不是“让模型知道业务定义”,而是“让模型先输出受控查询结构,再由系统执行”,换句话说,要做的是:
系统能不能稳定、可信地生成符合统一业务语义的查询和答案。
这一篇不是在追求“模型什么都能问”,而是在追求“系统先把最核心的一组问题稳定跑通”。
二、当前系统收敛的是高频问题类型
项目先收敛出一组真正有业务价值、能稳定复用的问题类型。
例如当前系统支持下面几类问题:
最近 90 天 Beauty 类目里,哪些价格带评论增长最快? 最近 90 天 Beauty 类目里,哪些价格带既增长快又差评率上升? 最近 30 天 Beauty 类目里,哪些商品的高帮助度差评最多? 最近 30 天差评率最高的商品有哪些? 最近 90 天评论增长快但评分不高的商品有哪些? Beauty 类目下不同价格带的评论量和平均评分如何?
这和智能问数类系统里常见的 demo 示例 prompt 实现机制不同。这里不是在展示“模型也许可以这样回答”,而是在收敛一组后续可以长期复用、可以继续提供给 Agent、Dashboard 和其他入口消费的分析接口。
读到这里,一个很自然的疑问是:如果当前只支持一组高频问题类型,那为什么还要做智能问数,直接用规则方法不就可以了吗?这样做是否不太智能?
关于这个问题,可以这样看:如果系统只需要回答几类完全固定的问题,那么很多场景下直接做规则接口、固定报表或者参数化查询,确实会更简单。但需要注意,我们收敛的是高频问题类型,而不是几句死板的固定问句;如果后面问题类型继续扩展、表达方式继续增多、入口继续增加,纯规则方法的维护成本会迅速上升,而“LLM 负责理解语言,受控 IR 负责约束执行”的结构会更容易继续往前走。
比如同一类问题,用户可以问:
最近 90 天 Beauty 类目里,哪个价格带评论涨得最快?
Beauty 类目近 90 天评论增长最快的是哪个价格段?
按价格带看,Beauty 类目最近 90 天评论增速最高的是哪个价格带?
这三句表面问法是不同的,却都可以落到同一个受控查询结构,如果只是兼容少量问法,规则匹配当然也能做;但随着问题类型、表达变体、业务对象和入口不断增加,纯规则方案的维护成本会很快上升。
自然语言变体很多,但最终收敛到有限的问题类型和有限的查询结构。
而“智能”的价值,就体现在自然语言理解、意图归类、槽位抽取和歧义消解,而不是自由发明查询。

三、查询流程
当前项目的问数查询流程,是这样:
用户问题 ↓ 识别意图 ↓ 映射到固定业务对象、指标、维度和条件 ↓ 生成受控 IR(当前实现为 Cube Query) ↓ 执行并生成答案
在这里,自然语言不直接决定 SQL,而是先被系统还原成一个正式意图。系统真正要识别的,不是用户用了哪种表述,而是这句话背后对应的是哪个业务对象、哪个指标、哪个维度、什么过滤条件、什么时间范围和什么排序方式。
继续用前面的例子:
最近 90 天 Beauty 类目里,哪些价格带评论增长最快?
这句话进入系统之后,真正会被还原成类似下面这样的结构:
核心指标:90 日评论增长率 辅助指标:90 日评论增量、评论总量 过滤条件:类目 = Beauty 时间范围:锚定到数据尾日回看 90 天 排序方式:按 90 日评论增长率降序
一旦意图先被还原成这个结构,问数层就不需要再“发明查询”,而只需要从语义层中引用已经正式定义过的成员,拼成一个可执行的受控 IR;在当前实现里,这个 IR 就是 Cube Query,类似下面结构。
{ "measures": [ "ProductDaily.commentGrowthRate90d", "ProductDaily.commentGrowth90d", "ProductDaily.commentCount" ], "dimensions": [ "ProductDaily.priceBand" ], "filters": [ { "member": "ProductDaily.category", "operator": "equals", "values": [ "Beauty" ] } ], "timeDimensions": [ { "dimension": "ProductDaily.date", "dateRange": [ "<data_end_minus_89d>", "<data_end>" ] } ], "order": { "ProductDaily.commentGrowthRate90d": "desc" }, "limit": 20 }
从系列实现的角度看,这一步非常关键。因为从这里开始,系统把“人类自由表达”正式连接到了“统一业务语义”,而中间不是靠提示词里的一次性约束或临场 SQL 拼装,而是靠受控映射。
四、“受控”具体约束什么
“受控 IR”不是一个抽象口号。落到当前这个项目里,它至少约束三件事。
1. 能用哪些指标、维度和条件,不由模型临场决定
问数层输出的是受控 IR,这意味着它只能引用语义层已经承认的成员。
也就是说:
能引用的指标是固定的
能引用的维度是固定的
能复用的 segments 是固定的
能使用的过滤条件和排序方式也在受控范围内
这背后的关键边界是:
问数层并不拥有业务口径,它只是负责把用户表达映射到语义层已经承认的业务口径。
这和“模型现场决定怎么查”完全不是一回事。
2. 输出的是受控 IR,而不是自由 SQL
在这个项目里,问数层最终输出的不是 SQL,而是一层受控的查询中间表示。
这件事看起来像是技术选型,但本质上是边界设计。因为一旦最终输出层是受控 IR,对查询执行的确定性约束就会更清楚:哪些成员可引用、哪些时间口径可用、哪些排序和过滤方式合法,都可以被明确审核。即便模型前面已经看过业务定义,最后也仍然只能提交一个在边界内的结构化请求,而不是一个自由执行指令。
这样做最大的好处,是把“自然语言的模糊性”和“查询执行的确定性”隔开了。自然语言当然可以有很多表达方式,但在系统真正执行之前,它必须先收敛成一套有限的正式结构。
3. 答案生成也不完全放开
很多 demo 在查询执行之后,最后一步会直接让模型自由总结。
这个项目现在也没有完全放开,而是先采用一个更简单但更稳的办法:根据不同 intent 的结果类型,生成对应的结构化摘要。
这一步虽然比较轻,但方向是明确的。因为对一个语义原生问数系统来说,答案不只是“把结果说得像人话”,它还应该逐渐具备下面这些能力:
说明核心结论
说明使用了哪些指标
说明时间范围
说明过滤条件
给出明细结果
后续逐步接入代表商品和代表评论等证据
也就是说,答案生成最终也不应该是一个完全脱离语义层的自由总结模块,而应该继续共享同一套业务解释边界。
五、到这里,这套问数层完成了什么
现在,这套问数层已经跑通了最小闭环,也验证了下面几件事。相关代码后续会开源到 GitHub:xuanagi,以及 www.xuanagi.com。
第一,智能问数不一定要从开放式 NL2SQL 起步。先做受控问句和受控 Planner,依然可以跑出真实可用的业务问数闭环。
第二,统一语义层是可以直接被自然语言消费的。只要问数层不绕开语义层,而是显式引用语义成员,那么自然语言问数和语义层之间就可以建立正式连接。
第三,问题空间是可以被逐步工程化收敛的。一开始不追求“什么都能问”,而是先把最核心的一组问题定义清楚,反而更利于后续扩展。
换句话说,到这里我们验证了:
人类可以基于统一语义稳定地问数。
结语
这一篇的核心是:
智能问数的核心原则,不是让模型自由生成任意查询,而是让系统稳定地产生符合统一业务语义的查询和答案。
到这里,前四篇已经基本把这套实现的最小闭环搭了起来:
公开数据 ↓ 可分析数仓 ↓ 统一语义层 ↓ 受控自然语言问数
但如果系统只是一个服务人类的问答接口,它和普通智能问数 demo 的差别仍然不大。
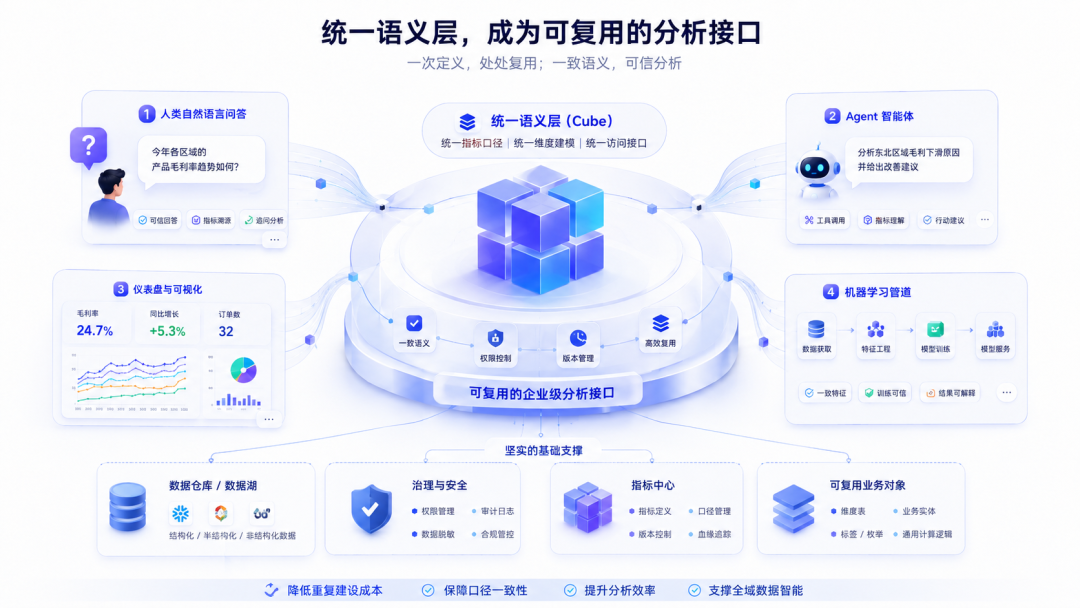
所以,下一篇要回答:
为什么同一套语义还应该继续服务 Agent、Dashboard 和 ML Pipeline?如果不能做到这一点,“语义原生”又到底还差什么?