当前很多企业都在做 Agent,在业务数据相关的场景里,智能问数是最典型的入口。原因很简单:只要 Agent 要回答经营、销售、财务、客户相关问题,就必须先解决一个基础问题——能不能准确取数。
这里说明下,企业业务 Agent (下文直接称为企业 Agent)可以粗分为两类:一类是以问数、分析、解释、报告为主的分析型 Agent;另一类是以审批、回写、流程触发、跨系统操作为主的执行型 Agent。
从主流 BI、智能问数和分析 Agent 产品路线看,语义层正在成为智能问数的核心基础。与此同时,为了解决可追溯、可解释、关系推理、文档上下文和执行治理等问题,业界也在引入更多技术:
本体、知识图谱、知识网络、数据目录、元数据、血缘、RAG
关于这些概念,很多人听完之后只有一个感受:
都很重要,但不知道先做哪个。
这篇文章尝试用一句话讲清楚:
对大多数企业 Agent 的第一阶段落地,收益最快、最大、最容易证明 ROI 的,通常是统一语义层。当 Agent 从“问数、解释、报告”走向“执行、审批、跨系统动作”时,本体、知识图谱、知识网络才会逐渐变成关键基础设施。
一、先解释几个概念
企业 Agent 落地里,最容易混淆的不是技术实现,而是概念边界。我们本节首先梳理一下这几个概念。
语义层、本体、知识图谱、数据目录、元数据、血缘、RAG 都和“让 AI 理解企业”有关,但它们解决的问题并不一样。
1. 数据目录:解决“数据在哪里,谁负责,能不能用”
数据目录像企业的数据资产地图,解决的是:数据资产可发现、可理解、可追溯、可治理。
它回答的是:
有哪些表?
有哪些字段?
谁是 owner?
字段是什么意思?
数据质量怎么样?
哪些报表用了这张表?
这个字段从哪里来,又流向哪里?
这份数据能不能给某个部门或 Agent 用?但它通常不直接回答:
收入怎么算?
毛利率怎么算?
活跃客户按什么口径?这些是语义层的问题。
2. 血缘:解决“数据从哪来,变更会影响谁”
血缘更像数据的物流轨迹,解决的是:追来源、看影响、做审计、定位数据质量问题。
它回答的是:
这张表由哪些上游表加工而来?
这个字段经过了哪些任务?
这个指标被哪些报表、模型、任务使用?
如果我改了这个字段,会影响哪些下游资产?但血缘也不直接解决“业务口径统一”。
3. 语义层:解决“指标怎么算,Agent 应该怎么问数”
语义层是企业数据和业务语言之间的翻译与治理层。
它回答的是:
收入到底怎么算?
GMV 是否包含退款?
活跃客户按登录、交易还是付费算?
毛利率用财务口径还是经营口径?
订单表和客户表怎么关联?
销售额可以按哪些维度分析?
哪些指标谁可以看?
Agent 查询时应该用哪个指标、哪个维度、哪个过滤条件?换句话说,语义层解决的是:
统一口径、统一指标、统一维度、统一关系、统一权限、统一查询入口。
这正是大多数分析型 Agent 第一阶段最需要的东西。
如果没有语义层,Agent 就会直接面对数据库表、字段、SQL 和散落在报表里的业务逻辑。结果很可能是:
SQL 是对的,但业务口径错了。
字段选对了,但指标含义错了。
表关联起来了,但粒度错了。
答案生成出来了,但和 BI 看板对不上。企业最难接受的地方也在这里:
Agent 回答得越自信,错起来越危险。
4. 知识图谱:解决“实体之间有什么关系”
知识图谱解决的是关系问题,解决的是:关系、多跳、关联推理、图检索。
知识图谱特别适合处理:
多跳关系
实体关联
路径分析
客户 360
供应链影响分析
设备故障影响链
风控与反欺诈
投研关系推理
GraphRAG如果第一批 Agent 主要是问:
上月收入是多少?
华东区毛利为什么下降?
生成一份销售复盘报告。知识图谱通常不是第一优先级。
不过,这里要加一个边界条件:
当归因问题需要跨客户、合同、订单、工单、供应链等实体链路时,可以提前建设轻量实体关系层或局部知识图谱。
也就是说,标准经营问数优先语义层;复杂实体关系分析,可以更早局部引入知识图谱。
5. 本体:解决“业务世界如何被 Agent 理解和操作”
本体比语义层和知识图谱更进一步,解决的是:业务对象、业务关系、状态流转、动作、权限、审批、风险、执行治理。
它不只是描述“数据是什么”和“关系是什么”,还要描述:
业务对象是什么;
对象有哪些属性;
对象之间有什么关系;
对象有哪些状态;
动作是否需要审批;
动作执行后有什么副作用;
动作执行后如何审计和回滚。它适合更高级的 Agent:
自动创建工单;
自动更新客户状态;
自动发起审批;
自动触发 KYC 补充材料流程;
自动处理供应链异常;
自动生成并提交月结差异单。对于这些场景,语义层是不够的。
因为语义层主要告诉 Agent:
这个指标怎么算。
而本体要告诉 Agent:
这个客户是谁,处于什么状态,和哪些对象有关,能不能执行这个动作,执行前要满足什么条件,执行后谁来审批,出了问题如何回滚。
二、主流厂商技术路线对比
为了一窥行业技术动向,本节整理了主流厂商智能问数的技术路线。
从这张表可以看出:
智能问数的核心和重点是语义层、指标层和可信查询资产;本体和知识图谱更多出现在跨域关系、复杂对象、业务动作和执行闭环场景里。
三、为什么应该先上语义层
1. 第一波 Agent 大多是分析型,不是执行型
从业务数据价值链看,企业 Agent 往往会沿着“分析 → 预测 → 决策 → 执行”逐步演进。所以企业第一波 Agent,最常见的是:
智能问数
经营分析
销售分析
财务分析
管理驾驶舱问答
指标解释
自动报告
异常归因
预算偏差分析这些 Agent 的主要任务不是改变业务系统状态,而是:
查数据
算指标
解释变化
比较趋势
生成报告
辅助决策它们最怕的不是“没有复杂本体”,而是“数字不可信”。
用户真正关心的是:
这个数从哪来?
是不是财务认可的口径?
是不是和 BI 看板一致?
有没有权限控制?
能不能追溯?
能不能复现?这些问题本质上是语义层问题。
2. 语义层的 ROI 更快、更清楚
语义层不是只给 Agent 用。
它可以同时服务:
BI 看板
智能问数
经营分析 Agent
财务分析 Agent
数据 API
报表系统
指标平台
数据产品
嵌入式分析一个指标定义好之后,不只是 Agent 能用,BI、报表、API、数据产品都能用。
这意味着语义层的投入可以复用到多个场景,也就是之前文章提到的统一语义层。
而本体往往要建模更复杂的业务对象、关系、状态和动作,组织协同成本更高,短期 ROI 更难证明。
3. 语义层边界更清楚,适合第一阶段落地
语义层在落地时可以只做这些东西:
核心指标
核心维度
核心事实表
核心关联关系
核心权限
核心业务术语
核心问法样例它不需要一开始覆盖整个企业。
比如销售经营分析 Agent,第一阶段只需要建:
收入
订单数
客单价
毛利
毛利率
新增客户
渠道
品类
销售团队这已经能支撑大量高频问题。
但如果一上来做本体,很容易陷入:
客户对象怎么定义?
合同对象怎么定义?
订单、发票、回款如何映射?
客户状态有哪些?
状态之间怎么流转?
哪些动作可以改变客户状态?
动作失败怎么回滚?
跨系统对象 ID 如何统一?这些当然重要,但容易把第一阶段项目拖成一个大型知识工程项目。
4. 本体不是语义层的替代品,而是工程上的扩展方向之一
这里需要避免一个误解:
本体不是语义层的替代品,也不是所有场景下都比语义层更高级。
从知识表示传统看,本体和语义层不是简单上下级关系,而是建模目标不同。
语义层更关注:
指标
维度
聚合
查询
权限
口径一致性本体更关注:
对象
关系
状态
规则
动作
流程
治理在企业 Agent 工程落地里,可以把本体看作语义层继续向对象语义、关系语义、规则语义和行动语义扩展后的一个重要方向。
更现实的建设路线通常是:
先有稳定的指标口径和语义模型
↓
再抽象业务实体、关系和规则
↓
再进入 ontology / graph / actions没有稳定指标口径,直接建本体,最后很可能得到一个漂亮但不好用的模型。
5. 语义层最能解决智能问数的高频错误
智能问数里最常见的错误通常是:
指标口径错
字段理解错
选表错
Join 错
时间口径错
聚合粒度错
权限错
SQL 看似正确但业务含义错这些问题最直接的治理手段是:
指标定义
字段描述
同义词
维度建模
Join 关系
样例 SQL
Verified Query
Verified Answer
Trusted Asset
Benchmark
权限规则主流厂商的路线已经很说明问题:
要让分析型 Agent 可靠,先把语义层和可信查询资产做好。
四、什么时候语义层不够,必须上知识图谱或本体
随着 Agent 能力升级,语义层会逐步不够用。
1. 复杂关系问题:需要知识图谱
如果问题是:
这个供应商出问题,会影响哪些订单、产品、客户和收入?
这些账户之间是否存在异常交易网络?
某个设备故障会影响哪些产线和交付计划?
某客户续约风险和合同、工单、投诉、付款记录之间有什么关系?这类问题的答案不在单个指标里,而在大量实体关系里。
这时知识图谱很有价值。
它可以表达:
客户—合同—订单—发票—回款—工单—投诉
供应商—物料—产品—订单—客户—收入
账户—设备—地址—交易—风险事件这不是传统指标语义层最擅长的。
2. 跨域推理问题:需要本体或类本体
如果 Agent 要跨多个业务域推理,比如:
客户成功 + 合同 + 财务 + 产品使用 + 工单 + 销售机会
供应链 + 库存 + 采购 + 生产 + 销售 + 交付
风险 + 法务 + 合同 + 账户 + 付款 + 审批这时需要一个更稳定的对象模型。
否则每个系统都有自己的“客户”“合同”“订单”“风险事件”,Agent 很难知道它们是不是同一个东西。
本体的价值就在于:
统一业务对象
统一对象属性
统一对象关系
统一状态与规则3. Agent 要执行动作:必须上本体和 Action Registry
只要 Agent 要改变业务系统状态,就不能只靠语义层。
比如:
创建工单
更新 CRM 客户状态
发起合同审批
提交付款申请
修改订单优先级
触发供应链预警
生成并提交月结差异单这时必须有:
对象模型
动作模型
权限模型
审批模型
风险模型
审计模型
回滚机制也就是:
Ontology + Action Registry + Policy + Audit当 Agent 从“给建议”走向“真执行”,本体就从增强项变成必需项。
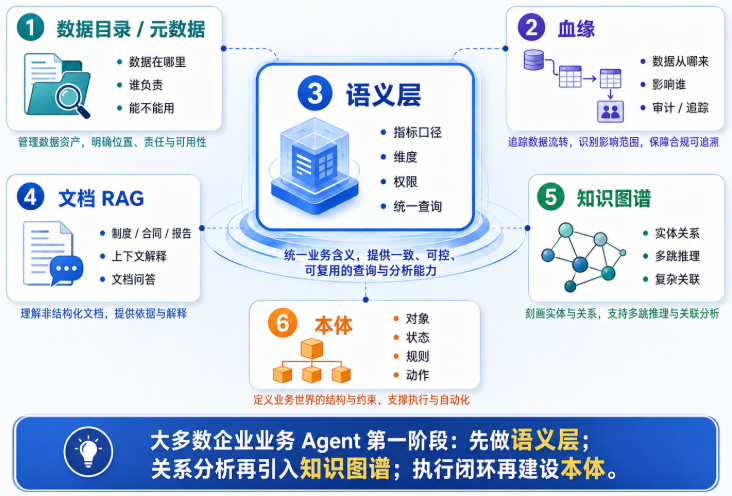
五、企业应该怎么分阶段建设
企业应该怎么分阶段建设 Agent 呢?比较现实的路线不是“大干快上企业本体”,而是分阶段。
• 第一阶段:选一个业务域,做轻量数据盘点 • 第二阶段:建设最小可用语义层 • 第三阶段:补问数知识库、样例问题和可信查询 • 第四阶段:补上下文知识 • 第五阶段:在高价值场景引入知识图谱 • 第六阶段:当 Agent 要执行动作,再建设本体和 Action Registry 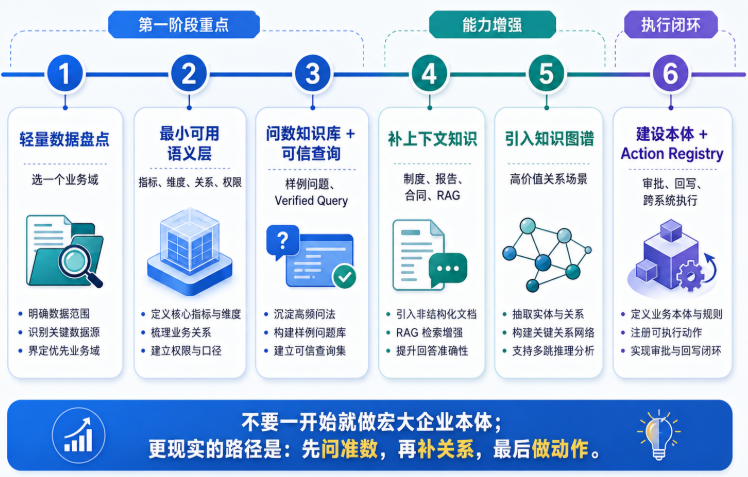
六、一张表讲清楚优先级
企业落地业务 Agent,应该首先落地高收益的技术。
可以总结成下面一段判断逻辑:
分析型 Agent:语义层优先。
文档型 Agent:RAG 优先。
关系型 Agent:知识图谱优先。
执行型 Agent:本体 + Action Registry 优先。
平台型 Agent:以上都要,但必须分阶段做。结语
根据分析->预测->决策->执行的基本逻辑,企业 Agent 的第一性问题不是:
我们有没有一个宏大的企业本体?而是:
Agent 能不能在正确权限下,先解决好一个场景的问题,用统一口径拿到可信数据,并给出可追溯、可复现、和 BI 一致的业务结论?解决这个问题,语义层是第一块最值得铺的地基。
相关阅读: