上一篇《语义原生智能问数系统落地实现(二):从公开数据到可分析数仓》讲清楚了:为什么从公开数据开始,为什么选择 All_Beauty,为什么原始工作层使用 Parquet,以及为什么正式分析层先收敛成商品、评论和商品日指标三张核心表。
但如果系统只停留在这里,它本质上还只是:
一套整理得比较规范的分析表。
这当然已经比直接读原始数据强很多,但它还没有解决这个项目最核心的问题:
人类问数、Agent 调用、Dashboard 展示和后续机器学习,如何才能真正共享同一套业务语义,而不是在不同地方各算各的?
这正是这一篇要进入的部分。
这篇的核心不是介绍一个工具,而是说明:
为什么语义层是这个项目真正的中心。
这一篇对应整个系列的第三步:在正式数仓之上,把业务对象、指标口径、关系和高频分析逻辑沉淀成可以被多个入口共享的正式语义。
一、为什么不能让模型直接连库
很多智能问数 demo 的默认路径是:
把数据库 schema 暴露给模型 ↓ 让模型直接生成 SQL ↓ 把查询结果再总结成答案
这个路径在演示阶段很直接,但很快会暴露几个问题:口径不稳定,同一个指标可能每次写出不同算法;多入口不一致,人类问数、Agent、Dashboard 和算法脚本各自一套逻辑;解释性差,很难稳定说明结果基于哪些指标和时间边界;维护成本也会快速上升。
所以更合理的路径不是“让模型学会怎么查表”,而是:
先把业务语义整理成正式系统能力,再让问数、Agent 和其他入口都围绕这套语义工作。
二、语义层到底在固化什么
这里的语义层,不是“给表起一个更友好的名字”,也不是“做一个字段注释文档”。
它真正固化的是四类东西:
第一类是业务对象:商品、评论、商品日指标分别是什么,它们之间是什么关系。
第二类是指标口径:评论数、平均评分、差评率、30 日评论速度、质量风险信号这些指标到底怎么定义。
第三类是查询逻辑:哪些过滤条件、时间窗口和聚合方式是被系统正式支持的。
第四类是复用边界:哪些定义要被问数、Agent、Dashboard 和 算法脚本 共同复用。
从这个角度看,语义层的职责不是“让查询更好看”,而是:
把未来会在多个入口反复使用的业务定义,提前沉淀成一套正式契约。
三、定义 products、reviews 和 productDailyMetrics
针对当前项目,Cube 语义层先围绕三个对象展开:
products reviews productDailyMetrics
这和上一篇的数据层设计是一一对应的。
products 对应商品维度。它定义了系统里的商品是谁、属于什么类目、处在什么价格带。
reviews 对应评论事实。它定义了评论计数、平均评分、差评数、已验证购买评论数和帮助度票数等评论级指标。
productDailyMetrics 对应商品日指标。它定义了趋势、变化率和启发式信号,为后续趋势问数和风险识别提供正式承载层。
这三个对象加在一起,可以支撑这套实现场景里的绝大部分问题:
哪个价格带增长更快? 哪个商品差评率更高? 哪些商品增长快但评分不高? 哪些商品机会信号更强? 哪些商品质量风险更高?
从“语义原生”的角度看,这一步的价值不只是“先建三个 cube”,而是:
先把当前最关键的业务对象和分析粒度稳定下来,再逐步扩展评论洞察、机会分数和证据链。
四、语义层包含哪些内容
当前项目 Cube 语义层除了包含必须的 measures 和 dimensions ,还包含:
segments
pre-aggregations
heuristic signal metrics
这背后对应的是三个判断。
1. segments 不应该总由问数层临时拼
例如:
negativeReviews verifiedReviews helpfulReviews activeDays risingNegativeRate
这些都不是一次性过滤条件,而是高频会被复用的业务切片。
如果每次都在问数层、Agent 提示词或者前端查询里临时拼出来,不是确定性查询,那么这些切片的定义迟早会分叉。
把它们沉淀进语义层,等于是在说:
这不是某一次查询的技巧,而是业务系统正式承认的复用语义。
2. pre-aggregations 不是后期才考虑的优化
在很多系统里,预聚合会被当作后期性能优化再考虑。
但在 Cube 里,它还有另一层意义:它让语义层不只是“把仓库查询转发出去”,而是天然承载高频分析模式。
例如按价格带、按商品、按天的滚动分析,本身就是后续问数和 Dashboard 中最可能被反复使用的模式。把这些模式用预聚合固定下来,等于是在语义层里提前承认:
哪些分析路径是系统核心使用路径,并进行查询加速。
3. 启发式信号
现在项目增加了启发式业务信号:
opportunitySignalScoreAvgqualityRiskScoreAvg
它们代表了一个重要方向:语义层不只服务“原始指标查询”,还要开始承载可复用的业务解释。
也就是说,系统不再只是回答“评论量是多少”,而是可以回答“哪些商品更值得关注”“哪些商品风险更高”。
五、为什么说语义层是多入口一致性的中心
这个项目一直强调,人类问数、Agent 调用、Dashboard 展示和 算法特征生成应该共享同一套业务语义。
这句话真正落地,靠的是语义层。
因为只有语义层才能真正稳定地回答这些问题:
评论增长到底看什么指标
差评率到底怎么定义
高帮助度差评到底怎么筛
机会信号到底怎么计算
时间范围到底怎么锚定
如果这些定义只存在于:
某个问数接口里
某段提示词里
某个 Notebook 里
某个 Dashboard SQL 里
那系统就是分裂的。
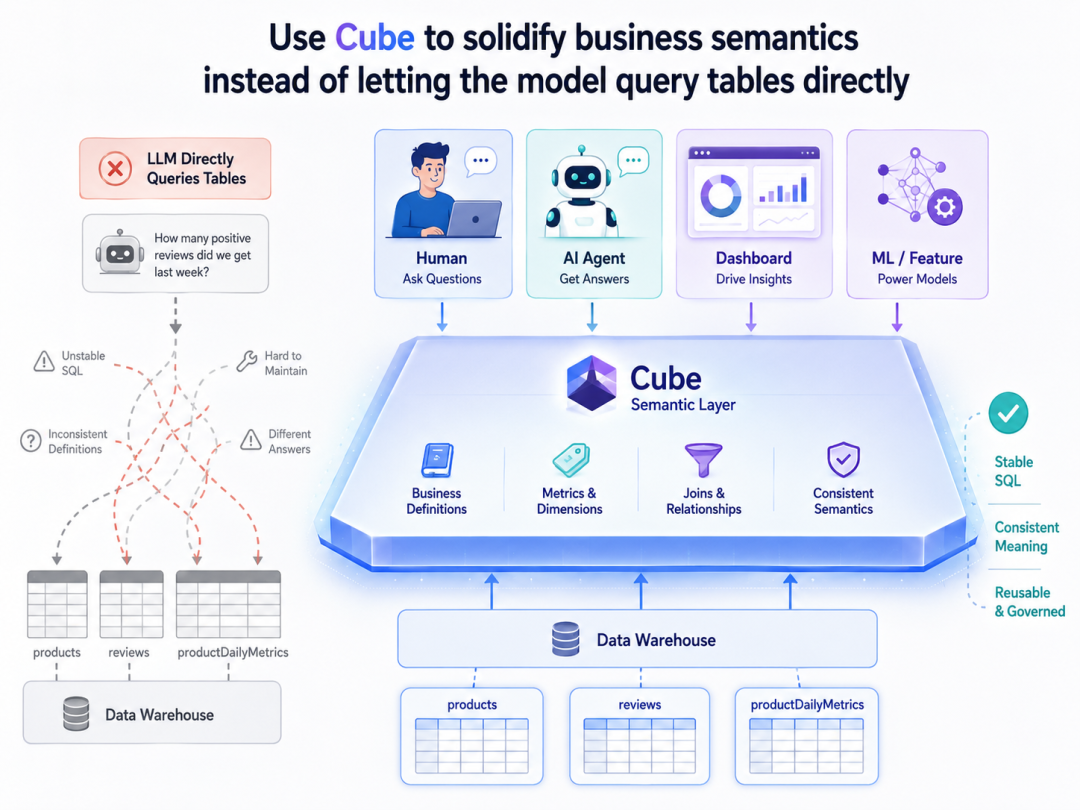
语义层的真正价值在于,它让这些定义开始脱离“某一次调用”,变成“整个系统都可以共享的正式定义”。
只要你希望多个入口共享同一套业务口径,你就一定需要一层正式的语义承载层。
结语
上一篇解决的是“有没有正式数仓”,这一篇解决的是“数仓之上的业务语义如何被正式定义”。
到这里,我们有了几张表,而且有了:
商品、评论和商品日指标这三个正式业务对象
一批统一口径的指标和维度
可复用的 segments
可复用的 pre-aggregations
可复用的启发式业务信号
但有了统一语义层之后,下一步还不是让模型随便生成 SQL。
下一篇要解决的问题是:
当这些指标、维度、切片和信号都已经被正式定义之后,人类的自然语言问题,应该怎样被收敛成受控、稳定、可解释的查询结构?
本系列项目代码将在 https://tools.agentstack.space 开源,感兴趣的朋友可以关注。