前面我们把这个项目的主干搭了起来:
项目背景和数仓选择
建设统一语义层
基于受控 IR 的问数层
并在上一篇验证了:
人类可以基于统一业务语义稳定地问数。
但如果项目只停在这一步,它和普通智能问数 demo 的差别仍然不大。
这个项目的初衷,也不只是“人类可不可以自然语言查数”,而是:
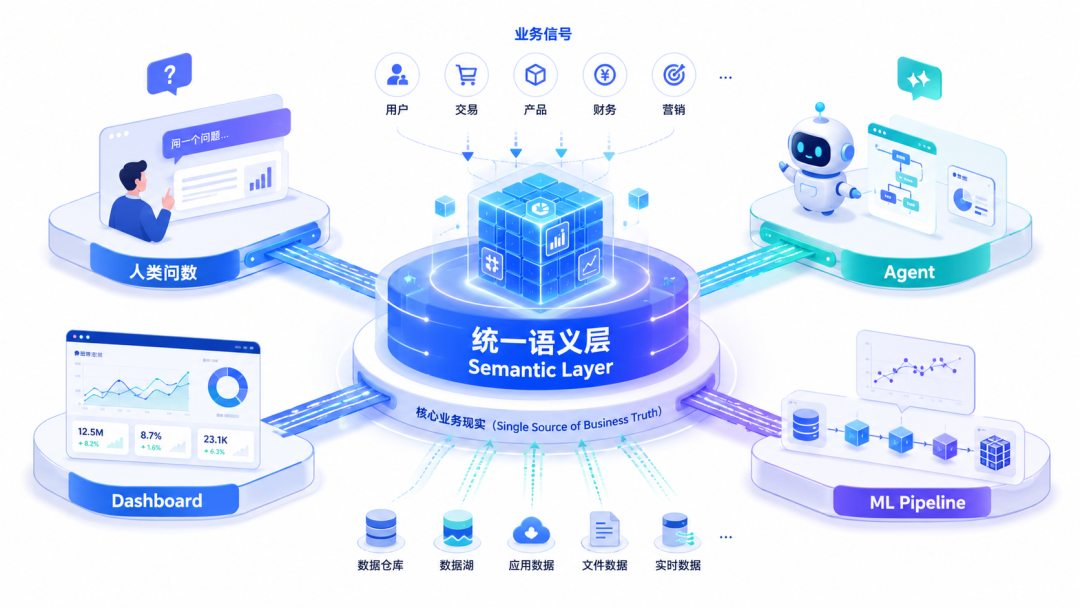
同一套业务语义,能不能同时服务人类问数、Agent 调用、Dashboard 展示和机器学习?
这一篇往前推进的问题是:在智能时代,统一语义不应停留在问数接口,而应该继续服务多个智能系统入口。
一、问数是入口,不是终点
如果把智能问数看成一个单独功能,那么前四篇的闭环其实已经足够:
自然语言问题 ↓ 受控 Planner ↓ Cube Query ↓ 答案生成
但问题是,真实业务系统很少只停在“问一个问题”。
问数本身当然有价值,它可以帮助人类更快发现信号、理解现状、辅助判断。只是从更长的业务链条看,问数通常不会是终点,而更像是一个入口:用户希望的不只是“知道发生过什么”,还希望系统继续支持观察、分析、决策、执行和优化。
只要系统想往前走,它几乎一定会继续出现三类需求:让 Agent 主动做分析、判断和执行;固定视图展示,把高频问题沉淀成仪表盘和风险面板;特征复用,把这些指标和信号继续送进模型处理流程。
如果这些需求各自建一套逻辑,那么系统虽然表面上功能更丰富了,底层却会分裂:
问数接口一套口径
Agent 一套口径
Dashboard 一套口径
ML pipeline 再一套口径
最后每个地方都能跑,但没有一个地方真正可靠。
所以,问数只是一个最先跑通的入口。从更大的价值看,统一语义的意义是让后续更高价值的能力都建立在同一套业务语义之上。
二、多个入口基于统一语义层
表面上看,Agent、Dashboard 和 ML 是三类不同能力;但本质上,它们其实都在做同一件事:定义业务语义。如果这件事不交给统一语义层,系统会很快变分裂。
Agent 作为智能时代的执行者,不能绕过语义层
现在大家都看到了智能时代的工作模式变化:具体业务的执行越来越多会是智能体,人类更多负责定义目标、编排智能体、审核结果。
然而如果 Agent 要开始自主分析、判断以及执行,首先要确保的,便是访问业务语义的方式必须稳定、可信,而这背后依赖的正是语义层。
与前面讲问数层时一样,Agent 同样不应该直接连数据库,也不应该绕过语义层自己决定查询结构。只不过到了 Agent 场景,对稳定和可信的要求会更高:问数接口即便答错,通常还是一次性的;Agent 一旦接进工作流,错误很可能会继续向下游传播。对于执行型系统来说,真正危险的地方不是它会不会说,而是它是否稳定。
例如:
误判哪个价格带更值得做 ↓ 误判哪些商品存在机会 ↓ 生成错误的分析结论 ↓ 输出错误的 listing 建议
如果 Agent 直接查库,那么它不仅会面临口径不稳的问题,还会面临“每个任务都重新解释业务定义”的问题。今天这样理解,明天那样理解,同一个指标在不同任务里换一种意思,这样的 Agent 即便看上去很聪明,也很难真正稳定进入业务流程。
更合理的办法,是让 Agent 通过一层经过语义层约束的语义化接口来完成这些分析与调用,例如:
ask_metric find_opportunity_products detect_quality_risk_products analyze_competitor_reviews generate_listing_brief
这些接口的意义在于:输入边界稳定,内部引用的指标定义稳定,输出结果也还能被继续审核。
也就是说,Agent 在这里不是“自己理解数据库”,而是:
通过一层明确的语义化接口,访问系统已经统一好的业务语义。
从这个角度看,语义层对 Agent 的意义,已经不只是一个分析辅助层,而是在智能体真正进入业务流程之前,先为它提供一层稳定的业务约束。
Dashboard 是高频问题的固定视图
过去很多团队里,Dashboard 和问数系统往往是两套并行建设的东西,通常还会专为 Dashboard 、甚至其中的每个模块针对性建表洗数据。短期看当然能跑,但长期很容易出现一个问题:
用户在图表里看到的结果,和在问数系统里问出来的结果,不一定完全一致。
只要存在这种情况,整个系统的可信度就会迅速下降。而要保持各应用一致,维护代价会很大。
合理的做法,是 Dashboard 卡片和图表都直接引用语义层里正式定义过的指标,和问数接口之间天然保持一致。
换句话说,Dashboard 的真正价值不只是“可视化”,而是:
把语义层里已经被验证过的高频问题,进一步沉淀成固定的观察面板。
ML Pipeline 不应重新定义一套业务语义
很多系统在接机器学习时,最容易发生的一件事就是重新分家。
业务分析一套逻辑,训练脚本一套逻辑,特征工程再一套逻辑。最后模型确实训出来了,但很难再说清楚:训练时用的“评论增长”“机会信号”和产品里看到的到底是不是同一种定义。
这也是这个项目一开始就强调的一点:
机器学习特征也应该从语义层获取,而不是训练脚本自己单独定义一套查询逻辑。
这不是为了形式统一,而是为了真正解决三个问题。
第一,训练与在线口径一致。
如果模型学到的是一套和业务系统不同的特征定义,那么它很难长期稳定服务业务。
第二,特征可追溯。
当模型结果需要解释时,至少应该能往回追到:这个分数依赖了哪些正式业务指标。
第三,后续维护成本更低。
如果未来调整了差评定义、价格带定义、风险信号公式,只改语义层通常比同时改十几份训练脚本和下游查询要可控得多。
因此,对机器学习来说,语义层的意义不只是“方便取数”,而是:
把业务系统和训练系统都绑定到同一套正式分析定义上。
但只讲到这里,还停留在原则层。对于这个具体项目来说,还要继续回答一个更落地的问题:如果真的要让 Agent、Dashboard 和 ML 基于同一套语义继续往前走,当前实现里最缺的到底是哪一层?
缺的不是再多几个指标,而是结构化指标和评论文本证据之间的正式连接。
三、要让多个入口继续共享同一套语义,还缺哪一层
回到项目代码,到目前为止,项目里已经有了商品、评论和商品日指标,也已经有了趋势和启发式信号。要继续往 Agent、Dashboard 和 ML 的方向推进,项目里还需要补上一层连接评论证据和结构化语义的中间表:
fact_review_insights
可以把它理解成一张评论语义增强事实表。它不是原始评论表,也不是最终指标表,而是把评论文本进一步整理成可复用的结构化洞察结果,例如评论对应的情绪、涉及的方面、归纳出的 pain point、证据片段,以及后续可以继续扩展的方面聚类、风险标签和机会标签。
从粒度上看,这张表记录的不是“某个商品总体怎么样”,而是“某条评论里识别出了什么语义事实”。一条评论如果同时涉及包装、气味、效果,理论上就可以拆成多条可复用的 insight 记录。
例如:
review_id = R123 aspect = 包装 pain_point = 包装泄漏 sentiment = negative evidence_span = "the bottle leaked during shipping"
这样一来,问数系统可以引用代表性证据,Agent 可以分析痛点分布,Dashboard 可以展示方面聚类结果,ML 也可以继续消费这些结构化特征。
换句话说,它可以被理解成评论文本和上层业务语义之间的一层正式翻译层。
这张表的重要性不在于“又多一张表”,而在于它可能成为评论文本语义和系统结构化分析之间的桥梁。
例如一条差评,不应该永远只作为一段原始文本存在。它还可以逐步被增强成:
sentiment = negative aspect = 包装 pain_point = 包装泄漏 evidence_span = "the bottle leaked during shipping"
一旦系统有了这样一层,后面很多事情才真正开始变得可能:
问数系统返回代表性证据
Agent 分析差评集中在哪些方面
Dashboard 展示负面方面分布
ML pipeline 使用 aspect / pain point 相关特征
所以从架构角度看,fact_review_insights 是“从结构化指标系统走向证据驱动系统”的关键中间层。
结语
这一篇说明的是:
统一语义的价值,不是让一个问答接口更规范,而是让人类、Agent、Dashboard 和 ML 基于同一套业务语义工作。
如果说前四篇的核心问题是“这套系统怎么建”,那么这一篇的核心问题就是:
为什么统一语义不应该只服务一个问答接口,而应该成为整个业务系统的共享取数基础设施?
而当这个问题被继续往上追问时,最终会落到智能时代应该如何正确构建企业 Agent:
如果智能问数、Agent 工具、Dashboard 和 ML Pipeline 最终共享同一套业务语义,那么“智能问数”本身是不是就不该被理解成一个孤立功能,而更应该被理解成智能时代企业业务 Agent 的一个基础能力?
这也和之前《从 Anthropic Financial-Services 看通用企业 Agent 架构》里讨论过的观点相呼应。
完整代码将开源在 github: xuanagi